Feed: Planet big data.
Author: Praveen Sripati.
In the previous blog, we looked at converting the Airline dataset from the original csv format to the columnar format and then run SQL queries on the two data sets using Hive/EMR combination. In this blog we will process the same data sets using Athena. So, here are the steps.
Step 1 : Go to the Athena Query Editor and create the ontime and the ontime_parquet_snappy table as shown below. The DDL queries for creating these two tables can be got from this blog.

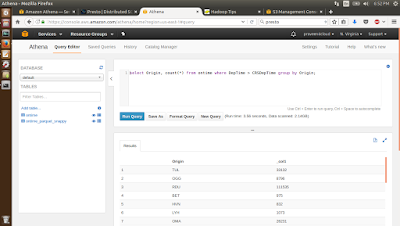
Step 2 : Run the query on the ontime and the ontime_parquet_snappy table as shown below. Again the queries can be got from the blog mentioned in Step 1.

Step 3 : Go to the Catalog Manager and drop the tables. Dropping them will simply delete the table definition, but not associated data in S3.

Just out of curiosity I created the two tables again and run a different query this time. Below are the queries with the metrics.
select distinct(origin) from ontime_parquet_snappy; Run time: 2.33 seconds, Data scanned: 4.76MB select distinct(origin) from ontime; Run time: 1.93 seconds, Data scanned: 2.14GB
As usual the there is not much difference in the time taken for the query execution, but the amount of data scanned in S3 for the Parquet Snappy data is significantly lower. So, the cost to run the query on the Parquet Snappy format data is significantly less.