Feed: Planet MySQL
;
Author: Geir Hoydalsvik
;
The MySQL Development team is very happy to announce that MySQL 8.0.3, the first 8.0 Release Candidate (RC1), is now available for download at dev.mysql.com (8.0.3 adds features to 8.0.2, 8.0.1 and 8.0.0). The source code is available at GitHub. You can find the full list of changes and bug fixes in the 8.0.3 Release Notes. Here are the highlights. Enjoy!
Histograms
Using histogram statistics in the optimizer (WL#9223) – This work by Erik Froseth makes use of histogram statistics in the optimizer. The primary use case for histogram statistics is for calculating the selectivity (filter effect) of predicates of the form “COLUMN operator CONSTANT”. Optimizer statistics are available to the user through the INFORMATION_SCHEMA.COLUMN_STATISTICS table.
Force Index
FORCE INDEX to avoid index dives when possible (WL#6526) – This work by Sreeharsha Ramanavarapu allows the optimizer to skip index dives in queries containing FORCE INDEX. An index dive estimates the number of rows. These estimates are used to decide the choice of index. When FORCE INDEX has been specified, this estimation is irrelevant and can be skipped. This applies to a single-table query during execution if FORCE INDEX applies to a single index, without sub-queries, without fulltext index, without GROUP-BY or DISTINCT clauses, and without ORDER-BY clauses.
This optimization applies to range queries and ref. queries, for example a range query like: SELECT a1 FROM t1 FORCE INDEX(idx) WHERE a1 > 'b';. In these cases, an EXPLAIN FOR CONNECTION FORMAT=JSON will output "skip_records_in_range_due_to_force": true and an optimizer trace will output "skipped_due_to_force_index".
Hints
Hint to temporarily set session variable for current statement (WL#681) – This work by Sergey Glukhov implements a new optimizer hint called SET_VAR. The SET_VAR hint will set the value for a given system variable for the next statement only. Thus the value will be reset to the previous value after the statement is over. SET_VAR covers a subset of sessions variables, since some session variables either do not apply to statements or must be set at an earlier stage of statement execution. Some variable settings have much more meaning being set for a query rather than for a connection, for example you might want to increase sort_buffer_size before doing a large sort query but it is very likely other queries in a session are simple and you are quite OK with default settings for those. E.g. SELECT /*+ SET_VAR(sort_buffer = 16M) */ name FROM people ORDER BY name;
Invisible Indexes
Optimizer switch to see invisible indexes (WL#10891) – This work by Martin Hansson implements an optimizer_switch named use_invisible_indexes which can be turned ON or OFF (default). Optimizer switches can be activated on a per session basis by SET @@optimizer_switch='use_invisible_indexes=on'; This feature supports the use case where a user wants to roll out an index. For example, the user may want to create the index as invisible and then activate the index in a specific session to measure the effect.
Common Table Expressions
Limit recursion in CTE (WL#10972) – This work by Guilhem Bichot implements a global and session variable called cte_max_recursion_depth to limit recursion in CTEs (default 1000, min 0, max 4G). This is done to protect the users from runaway queries, for example if the user forgets to add a WHERE clause to the recursive query block. When a recursive CTE does more than cte_max_recursion_depth iterations, the execution will stop and return an error message.
Character Sets
Add Russian collations for utf8mb4 (WL#10753) – This work by Xing Zhang adds Russian collations utf8mb4_ru_0900_ai_ci and utf8mb4_ru_0900_as_cs for character set utf8mb4. The new collations sort characters of Russian language according to language specific rules defined by Unicode CLDR.
JSON
Add JSON_MERGE_PATCH, rename JSON_MERGE to JSON_MERGE_PRESERVE (WL#9692) – This work by Knut Anders Hatlen implements two alternative JSON merge functions, JSON_MERGE_PATCH() and JSON_MERGE_PRESERVE().
The JSON_MERGE_PATCH() function implements the semantics of JavaScript (and other scripting languages) specified by RFC7396, i.e. it removes duplicates by precedence of the second document. For example, JSON_MERGE('{"a":1,"b":2 }','{"a":3,"c":4 }'); # returns {"a":3,"b":2,"c":4}.
The JSON_MERGE_PRESERVE() function has the semantics of JSON_MERGE() implemented in MySQL 5.7 which preserves all values, for example JSON_MERGE('{"a": 1,"b":2}','{"a":3,"c":4}'); # returns {"a":[1,3],"b":2,"c":4}.
The existing JSON_MERGE() function is deprecated in MySQL 8.0 to remove ambiguity for the merge operation. See also proposal in Bug#81283.
GIS
Support SRID in InnoDB Spatial Index (WL#10439) – This work by Elzbieta Babij makes InnoDB Spatial Indexes aware of the Spacial Reference System (SRS) of the indexed column. The geography support in 8.0 needs to compare geometries using different formulas depending upon the SRS. Therefore, the index must know which SRS it is in in order to work correctly. When a spatial index is created InnoDB will do a sanity check that SRID for all rows are of the same type as specified by column. See Argument Handling by Spatial Functions.
Ellipsoidal R-tree support functions (WL#10827) – This work by Norvald Ryeng reimplements the R-trees support functions for Minimum Bounding Rectangles (MBR) operations in a way that supports both Cartesian and geographical computations. R-tree indexes on columns with Cartesian geometries use Cartesian computations, and R-tree indexes on columns with geographic geometries use geographic computations. If an R-tree contains a mix of Cartesian and geographic geometries, or if any geometries are invalid, the result of any operation on that index is undefined.
SRID type modifier for geometric types (WL#8592) – This work by Erik Froseth adds a new column property for geometric types to specify the SRID. For example SRID 4326 in CREATE TABLE t1 (g GEOMETRY SRID 4326, p POINT SRID 0 NOT NULL);. Values inserted into a column with an SRID property must be in that SRID. Attempts to insert values with other SRIDs results in an exception condition being raised. Unmodified types, i.e., types with no SRID specification, will continue to accept all SRIDs as before. The optimizer is changed so that only indexes on columns with the SRID specified will be considered in query planning/execution. The specified SRID is exposed in both INFORMATION_SCHEMA.GEOMETRY_COLUMNS and INFORMATION_SCHEMA.COLUMNS.
Resource Groups
Resource Groups (WL#9467) – This work by Thayumanavar Sachithanantha introduces global Resource Groups to MySQL. The purpose of Resource Groups is to decide on the mapping between user/system threads and CPUs. This can be used to split workloads across CPUs to obtain better efficiency and/or performance in some use cases. There are two default groups, one for user threads and one for system threads. Both default groups have 0 priority and no CPU affinity. DevOps/DBAs can create and manage additional Resource Groups with priority and CPU affinity using SQL CREATE/ALTER/DROP RESOURCE GROUP. Information about existing resource groups are found in INFORMATION_SCHEMA.RESOURCE_GROUPS. The user can execute a SQL query on a given resource group by adding the hint /*+ RESOURCE_GROUP(resource_group_name) */ after the initial SELECT, UPDATE, INSERT, REPLACE or DELETE keyword.
Performance Schema
Digest Query Sample (WL#9830) – This work by Christopher Powers makes some changes to the EVENTS_STATEMENTS_SUMMARY_BY_DIGEST performance schema table to capture a full example query and some key information about this query example. The column QUERY_SAMPLE_TEXT is added to capture a query sample so that users can run EXPLAIN on a real query and to get a query plan. The column QUERY_SAMPLE_SEEN is added to capture the query sample timestamp. The column QUERY_SAMPLE_TIMER_WAIT is added to capture the query sample execution time. The columns FIRST_SEEN and LAST_SEEN have been modified to use fractional seconds.
Instrumentation meta-data (WL#7801) – This work by Marc Alff adds meta-data for instruments in performance schema table SETUP_INSTRUMENT. Meta-data act as online documentation, to be looked at by users or tools. It adds columns for “properties”, “volatility”, and “documentation”.
Service for componets (WL#9764) – This work by Marc Alff exposes the existing performance schema interface as a service which can be consumed by components in the new service infrastructure. With this work, code compiled as a component (not as a “plugin”) can invoke the performance schema instrumentation.
Security
Caching sha2 authentication plugin (WL#9591) – This work by Harin Vadodaria introduces a new authentication plugin, caching_sha2_password, which uses a caching mechanism to speed up authentication.
A password is created (CREATE/ALTER USER) over a TLS protected connection. The server does multiple rounds of SHA256(password) with SALT and stores the “expensive” HASH in mysql.user.authentication_string. Note that only the expensive HASH is stored on server side, not the password. Then the “new user” initiates a authentication and gets a random number back from the server. The client sends a HASH based on this random number and the user provided password back to the server. The server then tries to verify the received HASH against the cached entry. If it is in the cache the authentication is ok, but the first time the user connects it will not be in the cache.
When the entry is not in the cache a full “expensive authentication” takes place: The client sends password on a TLS connection or encrypts the password using RSA keypair (password never sent without encryption). The server decrypts the password and creates the expensive HASH and compares it with mysql.user.authentication_string. If there is no match the server returns an error to the client, otherwise it creates a fast HASH and stores it in cache entry : ‘user’@’host’ -> SHA256(SHA256(password)) and returns ok back to the client. The next time the user is authenticated it will be fast since it will find the entry in the cache.
Password rotation policy (WL#6595) – This work by Georgi Kodinov introduces restrictions on password reuse. Restrictions can be configured at global level as well as individual user level. Password history is kept secure because it may give clues about habits or patterns used by individual users when they change their password. As previously, MySQL offers a password expiration policy which enforces password change based on time. MySQL also has the ability to control what can and can not be used as password. This work restrict password reuse and thus forces users to supply new strong passwords with each password change.
Retire skip-grant-tables (WL#4321) – This work by Kristofer Älvring disallows remote connections when the server is started with –skip-grant-tables. See also Bug#79027 reported by Omar Bourja.
Protocol
Make metadata information transfer optional (WL#8134) – This work by Ramil Kalimullin adds an option to turn off metadata generation and transfer for resultsets. Constructing/parsing and sending/receiving resultset metadata consumes server, client and network resources. In some cases the metadata size can be much bigger than actual result data size and the metadata is just not needed. We can significantly speed up the query result transfer by completely disabling the generation and storage of these data. This work introduces a new session variable called resultset_metadata which can either be FULL (default) or NONE. Clients can set the CLIENT_OPTIONAL_RESULTSET_METADATA flag if they do not want meta data back with the resultset. There are no protocol changes for clients that don’t set the CLIENT_OPTIONAL_RESULTSET_METADATA, such clients will operate as before.
Service Infrastructure
Component status variables as a service for mysql_server component (WL#10806) – This work by Venkata Sidagam provides a status variable service to components by the mysql_server component. The components can register, unregister, and get_variable to handle their own status variables. The component status variables will be added as status variables to the global names space of status variables.
Configuration system variables as a service for mysql_server component (WL#9424) – This work by Venkata Sidagam provides a system variable service to components by the mysql_server component. The components can register, unregister, and get_variable to handle their own system variables. The component system variables will be added as status variables to the global names space of system variables.
X Protocol / X Plugin
mysqlx.Crud.Update with MERGE_PATCH (WL#10797) – This work by Lukasz Kotula adds an operation type called MERGE_PATCH to the X Protocol Mysqlx.Crud.Update message. When the X Plugin handles the Mysqlx.Crud.Update message it uses the JSON_MERGE_PATCH() function in the server to modify documents. A document patch expression contains instructions about how the source document is to be modified producing a derived document. Document patches are represented as Mysqlx.Expr.Expr objects, as already defined in the X protocol. SQL mapping takes advantage of the JSON_MERGE_PATCH() function, which has the desired semantics for merging a “patch” document against another JSON document. In short, the mapping takes the form of: @result = JSON_MERGE_PATCH(source, @patch_expr) where @patch_expr is the expression generated for the patch object.
Mysqlx.Crud.Update on top level document (WL#10682) – This work by Grzegorz Szwarc modifies the existing Mysqlx.Crud.Update operation in the X Protocol / X Plugin. With this change the update operations (ITEM_REMOVE, ITEM_SET, ITEM_REPLACE, ARRAY_INSERT, ARRAY_APPEND) allow an empty document path to be specified. An empty document-path means that the update operates on the whole document. In other words, all operations that are executed through Mysqlx.Crud.Update can now operate on whole/root document. Any operation done on an existing document will preserve the existing Document ID.
Mysqlx.Crud.Find with row locking (WL#10645) – This work by Tomasz Stepniak adds a “locking” field to the Mysqlx.Crud.Find message. The X Plugin interprets the value under “locking” to activate the innodb locking functionality. There are three cases possible: 1) “locking” field was not specified, the interpretation of the message is the same as in old plugin (no locking activated). 2) “locking” was set to “SHARED_LOCK”, the interpretation of the message adds “LOCK IN SHARE MODE” to the generated SQL (triggering the innodb locking functionality), and 3) “locking” was set to “EXCLUSIVE_LOCK”, the interpretation of the message adds “FOR UPDATE” to the generated SQL (triggering the innodb locking functionality).
Spatial index type (WL#10734) – This work by Grzegorz Szwarc adds support for spatial indexes on GeoJSON data stored in JSON documents. Geographical coordinates in a document collection are represented in the GeoJSON format. GeoJSON data is converted to the GEOMETRY datatype by the X Plugin. GEOMETRY datatypes can be indexed by spatial indexes.
Full-Text index type (WL#10744) – This work by Grzegorz Szwarc makes adds support for Full-Text indexes on Documents. Full-Text indexes allows searching the entire document (or a sub-document) for any text value.
X Protocol expectations for supported protobuf fields (WL#10237) – This work by Lukasz Kotula introduces a new “condition key” to the X Protocol expectation mechanism. The client is going to send an “Expect Open” message containing message/fields tag chain and the server is going to validate if the field specified this way is present inside the definition of servers X Protocol message. This is done to ensure pipelining, message processing should be stopped when any message does not meet the expectation. This functionality helps to detect compatibility problems between the client application and the MySQL Server, when the server receives an X Protocol message containing a field that it doesn’t know.
X Protocol connector code extraction from mysqlxtest to libmysqlxclient (WL#9509) – This work by Lukasz Kotula implements a low level client/connector library that is going to be used by both internal and external components to connect to MySQL Server using the X Protocol. Hence the libmysqlxclient plays a similar role for X Protocol as libmysqlclient has done for the classic protocol.
Performance
Use CATS for scheduling lock release under high load (WL#10793) – This work by Sunny Bains implements Contention-Aware Transaction Scheduling (CATS) in InnoDB. The original patch was contributed by Jiamin Huang (Bug#84266). CATS helps in reducing the lock sys wait mutex contention by granting locks to transactions that have a higher wait in the dependency graph. The implementation keeps track of how many transactions are waiting for locks that are already acquired by a transaction and, recursively, how many transaction are waiting for those waiting transactions in the wait for graph. The waits-for-edge is “weighted” and this weight is used to order the transactions when scheduling the lock release. The weight is a cumulative weight of the dependencies.
Tablespaces
InnoDB: Stop using rollback segments in the system tablespace (WL#10583) – This work by Kevin Lewis changes the minimum value for innodb_undo_tablespaces to 2 and modifies the code that deals with rollback segments in the system tablespace so that it can read, but not create or update rollback segements in an existing system tablespace. In 8.0, rollback segements are moved out of the system tablespace and into UNDO tablespaces.
Rename a general tablespace (WL#8972) – This work by Dyre Tjeldvoll implements ALTER TABLESPACE s1 RENAME TO s2; A general tablespace is a user-visible entity which users can CREATE, ALTER, and DROP. See also Bug#26949, Bug#32497, and Bug#58006.
DDL
ALTER TABLE RENAME COLUMN (WL#10761) – This work by Abhishek Ranjan implements ALTER TABLE ... RENAME COLUMN old_name TO new_name;. This is an improvement over existing syntax ALTER TABLE CHANGE ... which requires re-specification of all the attributes of the column. The old/existing syntax has the disadvantage that all the column information might not be available to the application trying to do the rename. There is also a risk of accidental data type change in the old/existing syntax which might result in data loss.
Replication
Replication of partial JSON updates (WL#2955) – This work by Maria Couceiro implements an option to enable/disable partial JSON updates. If the user disables the option, the server must only write full JSON documents to the binary log, and never partial JSON updates. If the user enables the option, the server may write partial JSON updates to the after-image of Row Based Replication updates in the binary log when possible. It may also write full JSON documents, e.g. in case the server cannot generate a partial JSON update, or if the partial JSON update would be bigger than the full document.
Group Replication
Instrument threads in GCS/XCom (WL#10622) – This work by Filipe Campos instruments the GCS and XCom threads and exposes them automatically in performance schema table metrics. It is also a requirement that we do further instrumentation in XCom and GCS, such as mutexes and condition variables, as well as memory usage.
Change GCS/XCOM to have dynamic debugging and tracing (WL#10200) – This work by Alfranio Correia implements dynamical filtering for debugging and tracing messages per sub-system (i.e. GCS, XCOM, etc). Debugging can be turned on by SET GLOBAL group_replication_communication_debug_options='GCS_DEBUG_ALL';. Error, warning and information messages will be output as defined by the server’s error logging component. Debug and trace messages will sent to a file when group replication is in use. By default the file used as debug sink will be named GCS_DEBUG_TRACE and will be placed in the data directory.
Data Dictionary
Support crash-safe DDL (WL#9536) – This work by Bin Su and Jimmy Yang ensures crash-safe DDL for MySQL. This work materializes one of the main benefits of having one common transactional data dictionary for server and storage engine layers, i.e. it is no longer possible for Server and InnoDB to have different metadata for database objects.
Improve crash-safety of non-table DDL (WL#9173) – This work by Praveenkumar Hulakund ensures crash-safety of non-table DDLs. For example CREATE/ALTER/DROP FUNCTION/PROCEDURE/EVENT/VIEW.
Implicit tablespace name should be same as table name (WL#10436) – This work by Thirunarayanan Balathandayuth ensures that a CREATE TABLE creates an implicit tablespace with the same name. This is only for implicitly created tablespaces, the user can also create explicitly named tablespaces and create tables within explicitly named tablespaces.
Remove InnoDB system tables and modify the views of their information schema counterparts (WL#9535) – This work by Zheng Lai removes the InnoDB internal data dictionary (SYS_* tables). Some of the INFORMATION_SCHEMA information are based on SYS_* tables, for example information_schema.innodb_sys_tables and information_schema.innodb_sys_tablespaces. These information_schema tables are replaced with views over data dictionary tables.
Integrating InnoDB SDI with new data dictionary (WL#9538) – This work by Satya Bodapati ensures that the JSON formatted Serialized Dictionary Information (SDI) is stored in the InnoDB tablespaces. This work also assures that the SDI gets updated when meta-data are changed, e.g. because of an ALTER TABLE. There is also a tool ibd2sdi, which is able extract SDI from an InnoDB tablespace when the server is offline.
Meta-data locking for FOREIGN KEY tables (WL#6049) – This work by Dmitry Lenev implements meta-data locking for foreign keys. This involves acquiring metadata locks on tables across foreign key relationships so that conflicting operations are blocked as well as updating FK metadata if a parent table changes. This work is enabled by the common data dictionary which makes foreign keys visible to the server layer, thus to meta-data locking.
Implement INFORMATION_SCHEMA system views for FILES/PARTITIONS (WL#9814) – This work by Gopal Shankar implements new system views definition for INFORMATION_SCHEMA.PARTITIONS and INFORMATION_SCHEMA.FILES. These views read metadata directly from data dictionary tables.
Implement INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS as a system views over dictionary tables (WL#11059) – This work by Gopal Shankar implements new system views definition for INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS. This view reads metadata directly from data dictionary tables.
MTR Tests
Change Server General tests to run with new default charset (WL#10299) – This work by Deepa Dixit fixes MTR tests so they now run with the new default character set.
Add/Extend mtr tests for Replication/GR for roles (WL#10886) – This work by Deepthi E.S. adds MTR tests to ensure that Roles are replicated as expected. For example tests must verify that ROLES on replication users used in ‘CHANGE MASTER TO’work as expected for RPL/GR.
Add/Extend mtr tests for replication with generated columns and X plugin (WL#9776) – This work by Parveez Baig adds MTR tests to ensure that stored/virtual columns are replicated as expected. For example that replication shall not be affected when transactions involve stored or virtual columns.
Library Upgrade
Upgrade zlib libraries to 1.2.11 in trunk (WL#10551) – This work by Aditya A. upgrades the zlib library versions from zlib 1.2.3 to zlib 1.2.11 for MySQL 8.0.
Changes to Defaults
Autoscale InnoDB resources based on system resources by default (WL#9193) – This work by Mayank Prasad introduces a new option innodb_dedicated_server which can be set OFF/ON (OFF by default). If ON, settings for following InnoDB variables (if not specified explicitly) would be scaled accordingly innodb_buffer_pool_size, innodb_log_file_size, and innodb_flush_method. See also blog post Plan to improve the out of the Box Experience in MySQL 8.0 by Morgan Tocker.
Change innodb_autoinc_lock_mode default to 2 (WL#9699) – This work by Mayank Prasad changes the default of innodb_autoinc_lock_mode from sequential (1) to interleaved (2). This can be done because the default replication format is row-based replication. This change is known to be incompatible with statement based replication, and may break some applications or user-generated test suites that depend on sequential auto increment. The previous default can be restored by setting innodb_autoinc_lock_mode=1;
Change innodb_flush_neighbors default to 0 (WL#9631) – This work by Mayank Prasad changes the default of innodb_flush_neighbors from 1 (enable) to 0 (disable). This is done because fast IO (SSDs) is now the default for deployment. We expect that for the majority of users, this will result in a small performance gain. Users who are using slower hard drives may see a performance loss, and are encouraged to revert to the previous defaults by setting innodb_flush_neighbors=1.
Change innodb_max_dirty_pages_pct_lwm default to 10 (WL#9630) – This work by Mayank Prasad changes the default of innodb_max_dirty_pages_pct_lwm from 0 (%) to 10 (%). With innodb_max_dirty_pages_pct_lwm=10, InnoDB will increase its flushing activity when >10% of the buffer pool contains modified (‘dirty’) pages. The motivation for this default change is to trade off peak throughput slightly, in exchange for more consistent performance. We do not expect the majority of users to see impact from this change, but symptomatically query throughput may be reduced after a number of sustained modifications. Users who wish to revert to the previous behavior can set innodb_max_dirty_pages_pct_lwm=0. The value of zero disables the increased flushing heuristic.
Change innodb_max_dirty_pages_pct default to 90 (WL#9707) – This work by Mayank Prasad changes the default of innodb_max_dirty_pages_pct from 75 (%) to 90 (%). With this change, InnoDB will allow a slightly greater number of modified (‘dirty’) pages in the buffer pool, at the risk of a lower amount of free-able space for other operations that require loading pages into the buffer pool. However in practice, InnoDB does not have the same reliance on innodb_max_dirty_pages_pct as it did in earlier versions of MySQL because of the introduction of a new low-watermark heuristic. With innodb_max_dirty_pages_pct_lwm, flushing activity increases at a much earlier point (default: 10%). Users wishing to revert to the previous behavior can set innodb_max_dirty_pages_pct=70 and innodb_max_dirty_pages_pct_lwm=0.
Change default algorithm for calculating back_log (WL#9704) – This work by Abhishek Ranjan changes the algorithm used for the back_log default which is autosize (-1). The new algorithm is simply to set back_log equal to max_connections. Default value will be capped to maximum limit permitted by range of ‘back_log’ (65535). The old algorithm was to set back_log = 50 + (max_connections / 5).
Change max-allowed-packet compiled default to 64M (WL#8393) – This work by Abhishek Ranjan changes the default of max_allowed_packet from 4194304 (4M) to 67108864 (64M). The main advantage with this larger default is that fewer users receive errors about insert or query being larger than max_allowed_packet. Users wishing to revert to the previous behavior can set max_allowed_packet=4194304.
Change max_error_count default to 1024 (WL#9686) – This work by Abhishek Ranjan changes the default of max_error_count from 64 to 1024. The effect is that MySQL will handle a larger number of warnings, e.g. for an UPDATE statement that touches 1000s of rows and many of them give conversion warnings (batched updates). There are no static allocations, so this change will only affect memory consumption for statements that generate lots of warnings.
Enable event_scheduler by default (WL#9644) – This work by Abhishek Ranjan changes the default of event_scheduler from OFF to ON. This is seen as an enabler for new features in SYS, for example “kill idle transactions”.
Enable binary log by default (WL#10470) – This work by Narendra Chauhan changes the default of –log-bin from OFF to ON. Nearly all production installations have the binary log enabled as it is used for replication and point-in-time recovery. Thus, by enabling binary log by default we eliminate one configuration step for users (enabling it later requires a mysqld restart). By enabling it by default we also get better test coverage and it becomes easier to spot performance regressions.
Enable replication chains by default (WL#10479) – This work by Ganapati Sabhahit changes the default of log-slave-updates from OFF to ON. This causes a slave to log replicated events into its own binary log. This option ensures correct behavior in various replication chain setups, which have become the norm today. This is also required for Group Replication.
Deprecation and Removal
Remove query cache (WL#10824) – This work by Steinar Gunderson removes the query cache for 8.0. See also blog post Retiring Support for the Query Cache by Morgan Tocker. All related startup options and configuration variables are removed as well. HAVE_QUERY_CACHE will now return NO, so that well-behaved clients can check for this and behave accordingly. The SQL_NO_CACHE keyword will continue to exist, but will be ignored (no effect in the grammar). This is so that e.g. mysqldump can continue working.
Rename tx_{read_only,isolation} variables to transaction_{read_only,isolation} (WL#9636) – This work by Nisha Gopalakrishnan removes the system variables called tx_read_only and tx_isolation. Use transaction_read_only and transaction_isolation instead. This is done to harmonize wording with command-line format –transaction_read_only and –transaction_isolation as well as with other transaction related system varaibles like transaction_alloc_block_size, transaction_allow_batching, and transaction_prealloc_size. See also Bug#70008 reported by Simon Mudd.
Remove log_warnings option (WL#9676) – This work by Tatjana Nurnberg removes the old log-warnings option deprecated in 5.7. Use log_error_verbosity instead.
Remove ignore_builtin_innodb option (WL#9675) – This work by Georgi Kodinov removes the old ignore_builtin_innodb options deprecated in 5.6. Even when used, these options have had no effect since MySQL 5.6.
Remove ENCODE()/DECODE() functions (WL#10788) – This work by Georgi Kodinov removes the ENCODE() and DECODE() functions deprecated in 5.7. Use AES_ENCRYPT() and AES_DECRYPT() instead.
Remove ENCRYPT(), DES_ENCRYPT(), and DES_DECRYPT() functions (WL#10789) – This work by Georgi Kodinov removes the ENCRYPT(), DES_ENCRYPT(), and DES_DECRYPT() functions deprecated in 5.7. Use AES_ENCRYPT() and AES_DECRYPT() instead.
Remove parameter secure_auth (WL#9674) – This work by Georgi Kodinov removes the secure_auth deprecated in 5.7. The option appears in server and clients. Even when used, these options have had no effect since MySQL 5.7. The secure-auth was used to control whether the mysql_old_password methods are allowed on the client and the server but this authentication method is now gone from both the client and the server.
Remove EXPLAIN PARTITIONS and EXTENDED options (WL#9678) – This work by Sreeharsha Ramanavarapu removes the EXTENDED and PARTITIONS keywords from EXPLAIN deprecated in 5.7. Both EXTENDED and PARTITIONS output are enabled by default since 5.7, so these keywords are superfluous and thus removed.
Remove unused date_format, datetime_format, time_format, max_tmp_tables (WL#9680) – This work by Sreeharsha Ramanavarapu removes system variables date_format, datetime_format, time_format,and max_tmp_tables. These variables have never been in use (or at least not been used in MySQL 4.1 or newer releases).
Remove multi_range_count system variable (WL#10908) – This work by Sreeharsha Ramanavarapu removes the system variable multi_range_count deprecated in 5.1. Even when used, this option has had no effect since MySQL 5.5. From MySQL 5.5 and onwards, arbitrarily long lists of ranges can be processed.
Remove the global scope of the sql_log_bin system variable (WL#10922) – This work by Luis Soares removes the global scope of the sql_log_bin system variable in MySQL 8.0. The sql_log_bin was set read only in MySQL 5.5, 5.6 and 5.7. In addition, reading this variable was deprecated in MySQL 5.7. See also Bug#67433 reported by Jeremy Cole.
Deprecate master.info and relay-log.info files (WL#6959) – This work by Luis Soares implements a deprecation warning in the server when either relay-log-info-repository or master-info-repository are set to FILE instead of TABLE. The default setting is TABLE for both options and this is also the most crash-safe setup.
Deprecate mysqlbinlog –stop-never-slave-server-id (WL#9633) – This work by Luis Soares implements a deprecation warning in the mysqlbinlog utility for the –stop-never-slave-server-id option. Use the –connection-server-id option instead.
Deprecate mysqlbinlog- -short-form (WL#9632) – This work by Luis Soares implements a deprecation warning in the mysqlbinlog utility for the –short-form option. This option is not to be used in production (as stated in the docs) and is now too overloaded to be used even when testing.
Deprecate IGNORE_SERVER_IDS when GTID_MODE=ON (WL#10963) – This work by Luis Soares implements a deprecation warning when users try to use CHANGE MASTER TO IGNORE_SERVER_IDS together with GTID_MODE=ON. When GTID_MODE=ON, any transaction that has been applied is automatically filtered out, so there is no need for IGNORE_SERVER_IDS.
Deprecate expire_logs_days (WL#10924) – This work by Neha Kumari adds a deprecation warning when users try to set expire_logs_days. Use the new variable binlog_expire_log_seconds instead. The new variable allows users to set expire time which need not be a multiple of days. This is the better way to set the expiration time and also more flexible, it makes the system variable expire_logs_days superfluous.
That’s it for now. Thank you for using MySQL!








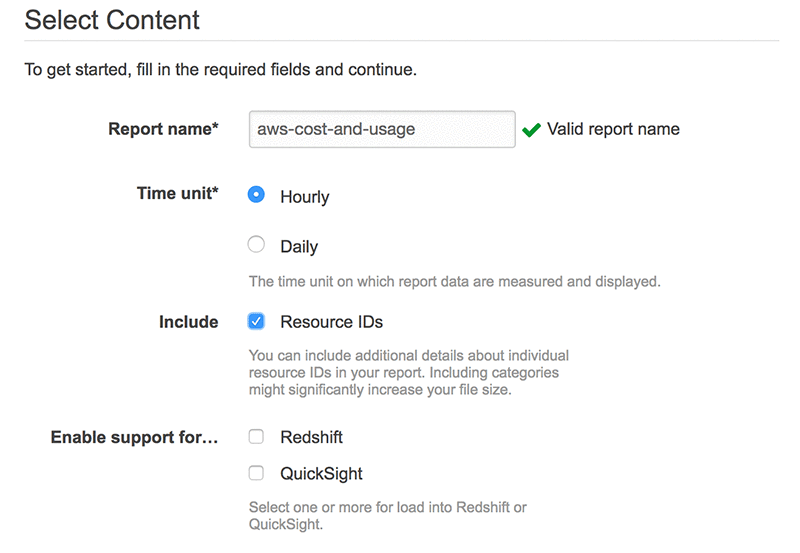

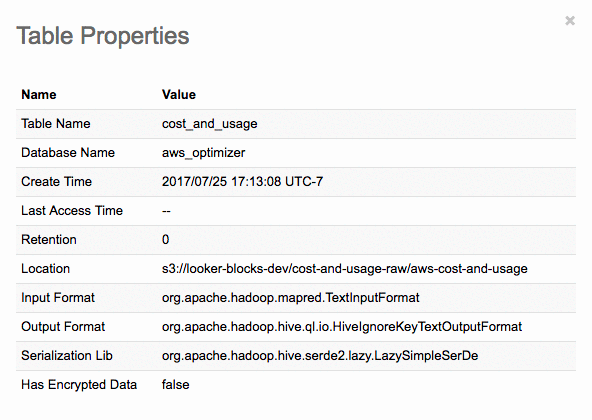

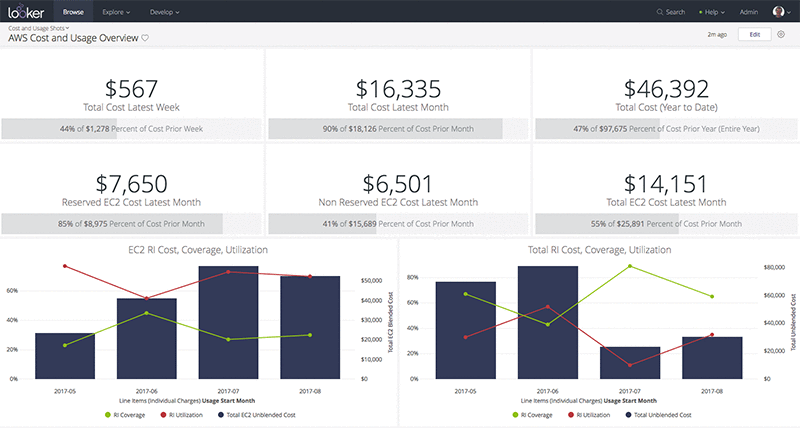

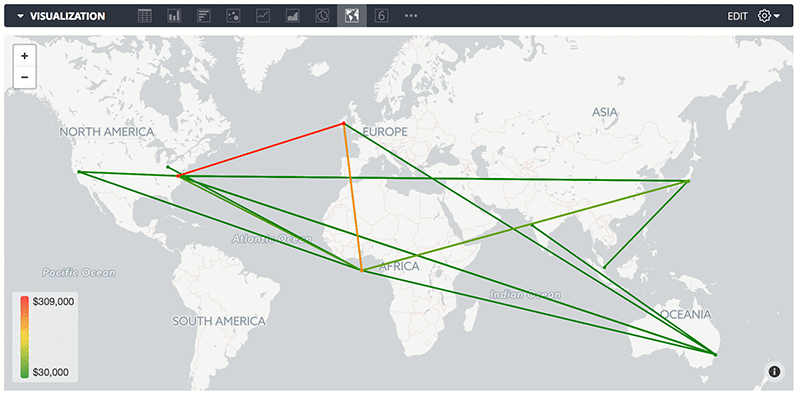
 Dillon Morrison leads the Platform Ecosystem at Looker. He enjoys exploring new technologies and architecting the most efficient data solutions for the business needs of his company and their customers. In his spare time, you’ll find Dillon rock climbing in the Bay Area or nose deep in the docs of the latest AWS product release at his favorite cafe (“Arlequin in SF is unbeatable!”).
Dillon Morrison leads the Platform Ecosystem at Looker. He enjoys exploring new technologies and architecting the most efficient data solutions for the business needs of his company and their customers. In his spare time, you’ll find Dillon rock climbing in the Bay Area or nose deep in the docs of the latest AWS product release at his favorite cafe (“Arlequin in SF is unbeatable!”).








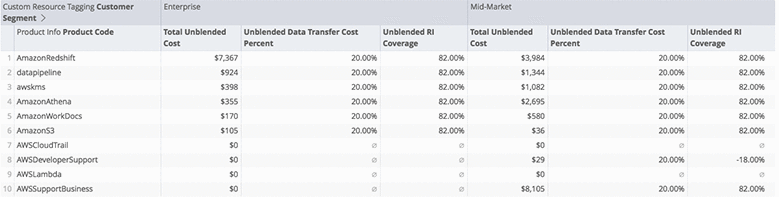
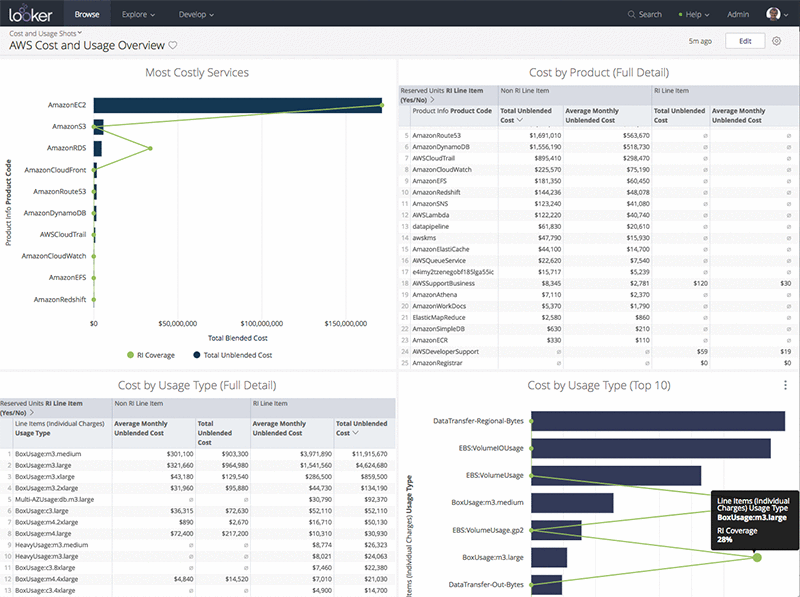
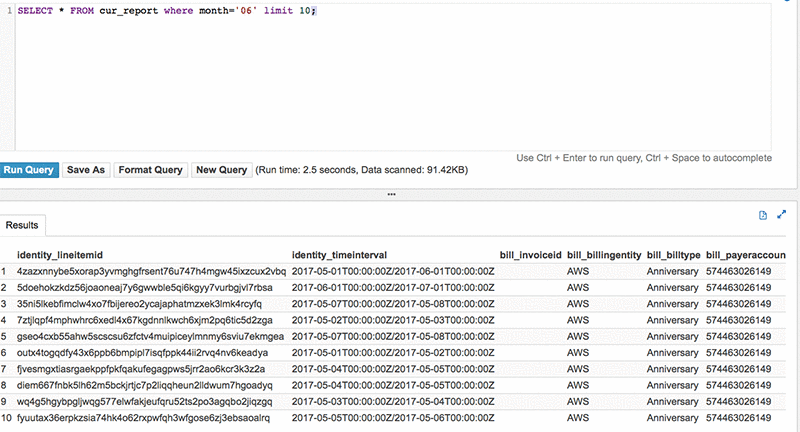
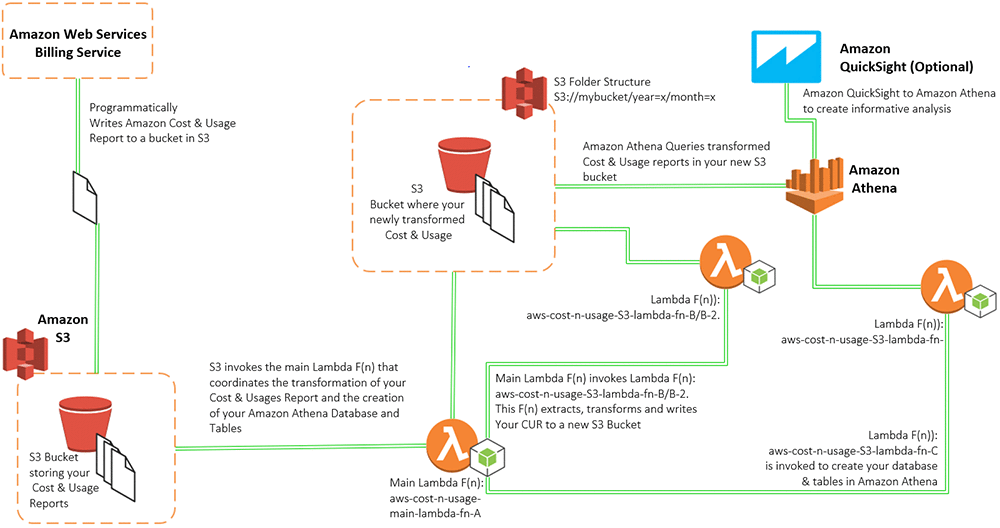
 100vw, 292px” data-recalc-dims=”1″/></a><figcaption class=) Collect Big SQL Logs
Collect Big SQL Logs 100vw, 640px” data-recalc-dims=”1″/></a><figcaption class=) Collect logs output
Collect logs output




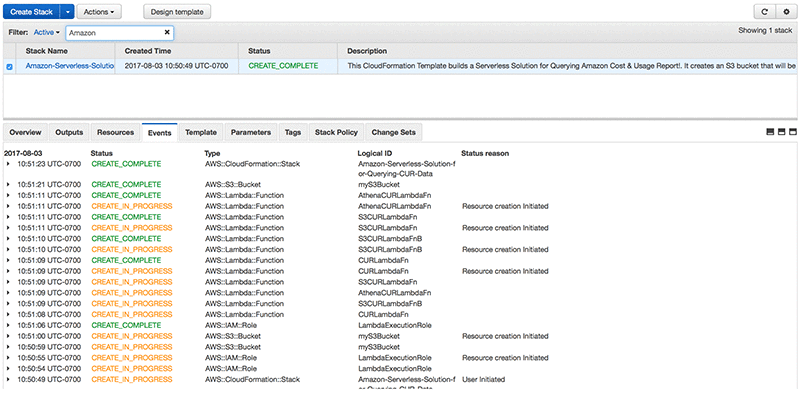
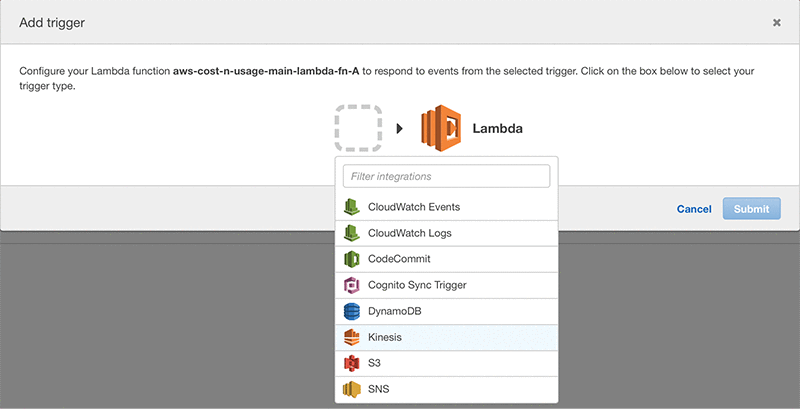
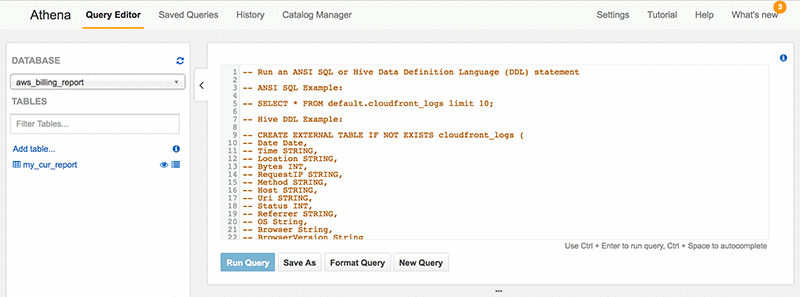
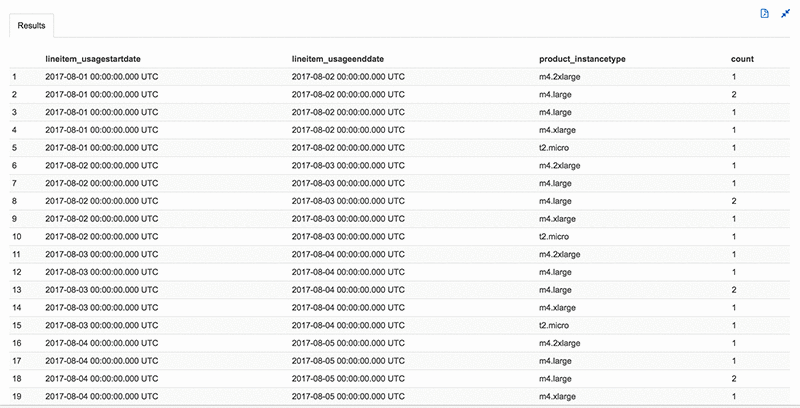

 Androski Spicer has been a Solution Architect with Amazon Web Services the past two and half years. He works with customers to ensure that their environments are architected for success and according to AWS best practices. In his free time he can be found cheering for Chelsea FC, Seattle Sounders, Portland Timbers or the Vancouver Whitecaps.
Androski Spicer has been a Solution Architect with Amazon Web Services the past two and half years. He works with customers to ensure that their environments are architected for success and according to AWS best practices. In his free time he can be found cheering for Chelsea FC, Seattle Sounders, Portland Timbers or the Vancouver Whitecaps.



































