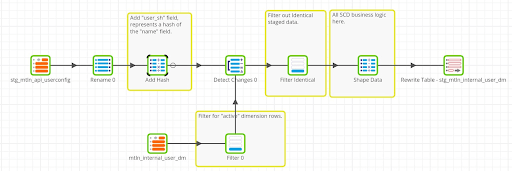
Feed: MariaDB Knowledge Base Article Feed.
Author: .
With InnoDB, it is somewhat common to see the following message as an error or warning:
ERROR 1118 (42000): Row size too large (> 8126). Changing some columns to
TEXT or BLOB may help. In current row format, BLOB prefix of 0 bytes is stored inline.
This message is raised in the following cases:
- If the
innodb_strict_mode system variable is set to ON, then InnoDB will raise an error with this message if a user or application executes a DDL statement that attempts to create or alter a table and that table’s definition would allow rows that the table’s InnoDB row format can’t actually store.
- If the
innodb_strict_mode system variable is set to OFF, then InnoDB will raise a warning with this message during the DDL statement instead. In this case, if a user or application actually tries to write a row that the table’s InnoDB row format can’t store, then InnoDB will raise an error with this message during the DML statement that attempts to write the row.
The root cause of the problem is that InnoDB has a maximum row size that is roughly equivalent to half of the value of the innodb_page_size system variable. See InnoDB Row Formats Overview: Maximum Row Size for more information.
InnoDB’s row formats work around this problem by storing certain kinds of variable-length columns on overflow pages. However, different row formats can store different types of data on overflow pages. Some row formats can store more data in overflow pages than others. For example, the DYNAMIC and COMPRESSED row formats can store the most data in overflow pages. To see how to determine how the various InnoDB row formats use overflow pages, see the following pages:
Checking Existing Tables for the Problem
InnoDB does not currently have an easy way to check which existing tables have this problem. See MDEV-20400 for more information.
Solving the Problem
If you encounter this error, then there are some solutions available.
Disabling InnoDB Strict Mode
The unsafe option is to disable InnoDB strict mode.
InnoDB strict mode can be disabled by setting the innodb_strict_mode system variable to OFF.
For example, even though the following table schema is too large for most InnoDB row formats to store, it can still be created when InnoDB strict mode is disabled:
SET GLOBAL innodb_default_row_format='dynamic';
SET SESSION innodb_strict_mode=OFF;
CREATE OR REPLACE TABLE tab (
col1 varchar(40) NOT NULL,
col2 varchar(40) NOT NULL,
col3 varchar(40) NOT NULL,
col4 varchar(40) NOT NULL,
col5 varchar(40) NOT NULL,
col6 varchar(40) NOT NULL,
col7 varchar(40) NOT NULL,
col8 varchar(40) NOT NULL,
col9 varchar(40) NOT NULL,
col10 varchar(40) NOT NULL,
col11 varchar(40) NOT NULL,
col12 varchar(40) NOT NULL,
col13 varchar(40) NOT NULL,
col14 varchar(40) NOT NULL,
col15 varchar(40) NOT NULL,
col16 varchar(40) NOT NULL,
col17 varchar(40) NOT NULL,
col18 varchar(40) NOT NULL,
col19 varchar(40) NOT NULL,
col20 varchar(40) NOT NULL,
col21 varchar(40) NOT NULL,
col22 varchar(40) NOT NULL,
col23 varchar(40) NOT NULL,
col24 varchar(40) NOT NULL,
col25 varchar(40) NOT NULL,
col26 varchar(40) NOT NULL,
col27 varchar(40) NOT NULL,
col28 varchar(40) NOT NULL,
col29 varchar(40) NOT NULL,
col30 varchar(40) NOT NULL,
col31 varchar(40) NOT NULL,
col32 varchar(40) NOT NULL,
col33 varchar(40) NOT NULL,
col34 varchar(40) NOT NULL,
col35 varchar(40) NOT NULL,
col36 varchar(40) NOT NULL,
col37 varchar(40) NOT NULL,
col38 varchar(40) NOT NULL,
col39 varchar(40) NOT NULL,
col40 varchar(40) NOT NULL,
col41 varchar(40) NOT NULL,
col42 varchar(40) NOT NULL,
col43 varchar(40) NOT NULL,
col44 varchar(40) NOT NULL,
col45 varchar(40) NOT NULL,
col46 varchar(40) NOT NULL,
col47 varchar(40) NOT NULL,
col48 varchar(40) NOT NULL,
col49 varchar(40) NOT NULL,
col50 varchar(40) NOT NULL,
col51 varchar(40) NOT NULL,
col52 varchar(40) NOT NULL,
col53 varchar(40) NOT NULL,
col54 varchar(40) NOT NULL,
col55 varchar(40) NOT NULL,
col56 varchar(40) NOT NULL,
col57 varchar(40) NOT NULL,
col58 varchar(40) NOT NULL,
col59 varchar(40) NOT NULL,
col60 varchar(40) NOT NULL,
col61 varchar(40) NOT NULL,
col62 varchar(40) NOT NULL,
col63 varchar(40) NOT NULL,
col64 varchar(40) NOT NULL,
col65 varchar(40) NOT NULL,
col66 varchar(40) NOT NULL,
col67 varchar(40) NOT NULL,
col68 varchar(40) NOT NULL,
col69 varchar(40) NOT NULL,
col70 varchar(40) NOT NULL,
col71 varchar(40) NOT NULL,
col72 varchar(40) NOT NULL,
col73 varchar(40) NOT NULL,
col74 varchar(40) NOT NULL,
col75 varchar(40) NOT NULL,
col76 varchar(40) NOT NULL,
col77 varchar(40) NOT NULL,
col78 varchar(40) NOT NULL,
col79 varchar(40) NOT NULL,
col80 varchar(40) NOT NULL,
col81 varchar(40) NOT NULL,
col82 varchar(40) NOT NULL,
col83 varchar(40) NOT NULL,
col84 varchar(40) NOT NULL,
col85 varchar(40) NOT NULL,
col86 varchar(40) NOT NULL,
col87 varchar(40) NOT NULL,
col88 varchar(40) NOT NULL,
col89 varchar(40) NOT NULL,
col90 varchar(40) NOT NULL,
col91 varchar(40) NOT NULL,
col92 varchar(40) NOT NULL,
col93 varchar(40) NOT NULL,
col94 varchar(40) NOT NULL,
col95 varchar(40) NOT NULL,
col96 varchar(40) NOT NULL,
col97 varchar(40) NOT NULL,
col98 varchar(40) NOT NULL,
col99 varchar(40) NOT NULL,
col100 varchar(40) NOT NULL,
col101 varchar(40) NOT NULL,
col102 varchar(40) NOT NULL,
col103 varchar(40) NOT NULL,
col104 varchar(40) NOT NULL,
col105 varchar(40) NOT NULL,
col106 varchar(40) NOT NULL,
col107 varchar(40) NOT NULL,
col108 varchar(40) NOT NULL,
col109 varchar(40) NOT NULL,
col110 varchar(40) NOT NULL,
col111 varchar(40) NOT NULL,
col112 varchar(40) NOT NULL,
col113 varchar(40) NOT NULL,
col114 varchar(40) NOT NULL,
col115 varchar(40) NOT NULL,
col116 varchar(40) NOT NULL,
col117 varchar(40) NOT NULL,
col118 varchar(40) NOT NULL,
col119 varchar(40) NOT NULL,
col120 varchar(40) NOT NULL,
col121 varchar(40) NOT NULL,
col122 varchar(40) NOT NULL,
col123 varchar(40) NOT NULL,
col124 varchar(40) NOT NULL,
col125 varchar(40) NOT NULL,
col126 varchar(40) NOT NULL,
col127 varchar(40) NOT NULL,
col128 varchar(40) NOT NULL,
col129 varchar(40) NOT NULL,
col130 varchar(40) NOT NULL,
col131 varchar(40) NOT NULL,
col132 varchar(40) NOT NULL,
col133 varchar(40) NOT NULL,
col134 varchar(40) NOT NULL,
col135 varchar(40) NOT NULL,
col136 varchar(40) NOT NULL,
col137 varchar(40) NOT NULL,
col138 varchar(40) NOT NULL,
col139 varchar(40) NOT NULL,
col140 varchar(40) NOT NULL,
col141 varchar(40) NOT NULL,
col142 varchar(40) NOT NULL,
col143 varchar(40) NOT NULL,
col144 varchar(40) NOT NULL,
col145 varchar(40) NOT NULL,
col146 varchar(40) NOT NULL,
col147 varchar(40) NOT NULL,
col148 varchar(40) NOT NULL,
col149 varchar(40) NOT NULL,
col150 varchar(40) NOT NULL,
col151 varchar(40) NOT NULL,
col152 varchar(40) NOT NULL,
col153 varchar(40) NOT NULL,
col154 varchar(40) NOT NULL,
col155 varchar(40) NOT NULL,
col156 varchar(40) NOT NULL,
col157 varchar(40) NOT NULL,
col158 varchar(40) NOT NULL,
col159 varchar(40) NOT NULL,
col160 varchar(40) NOT NULL,
col161 varchar(40) NOT NULL,
col162 varchar(40) NOT NULL,
col163 varchar(40) NOT NULL,
col164 varchar(40) NOT NULL,
col165 varchar(40) NOT NULL,
col166 varchar(40) NOT NULL,
col167 varchar(40) NOT NULL,
col168 varchar(40) NOT NULL,
col169 varchar(40) NOT NULL,
col170 varchar(40) NOT NULL,
col171 varchar(40) NOT NULL,
col172 varchar(40) NOT NULL,
col173 varchar(40) NOT NULL,
col174 varchar(40) NOT NULL,
col175 varchar(40) NOT NULL,
col176 varchar(40) NOT NULL,
col177 varchar(40) NOT NULL,
col178 varchar(40) NOT NULL,
col179 varchar(40) NOT NULL,
col180 varchar(40) NOT NULL,
col181 varchar(40) NOT NULL,
col182 varchar(40) NOT NULL,
col183 varchar(40) NOT NULL,
col184 varchar(40) NOT NULL,
col185 varchar(40) NOT NULL,
col186 varchar(40) NOT NULL,
col187 varchar(40) NOT NULL,
col188 varchar(40) NOT NULL,
col189 varchar(40) NOT NULL,
col190 varchar(40) NOT NULL,
col191 varchar(40) NOT NULL,
col192 varchar(40) NOT NULL,
col193 varchar(40) NOT NULL,
col194 varchar(40) NOT NULL,
col195 varchar(40) NOT NULL,
col196 varchar(40) NOT NULL,
col197 varchar(40) NOT NULL,
col198 varchar(40) NOT NULL,
PRIMARY KEY (col1)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
But if you look closely, you’ll see that InnoDB will still raise a warning with the same message:
MariaDB [db1]> SHOW WARNINGS;
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 139 | Row size too large (> 8126). Changing some columns to TEXT or BLOB may help. In current row format, BLOB prefix of 0 bytes is stored inline. |
+---------+------+----------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.000 sec)
As mentioned above, even though InnoDB is allowing the table to be created, there is still an opportunity for errors. If a user or application actually tries to write a row that the InnoDB row format can’t store, then InnoDB will raise an error during the DML statement that attempts to write the row. This creates a somewhat unsafe situation, because it means that the application has the chance to encounter an additional error while executing DML.
If the table is using either the REDUNDANT or the COMPACT row format, then a safe option is to convert it to use the DYNAMIC row format instead. If your tables were originally created on an older version of MySQL or MariaDB, then your table may be using one of these older row formats:
- In MySQL 4.1 and before, the
REDUNDANT row format was the default row format.
- In MariaDB 10.1 and before, the
COMPACT row format was the default row format.
The DYNAMIC row format can store more data on overflow pages than these older row formats, so converting your tables to use this row format can sometimes fix the problem.
For example:
ALTER TABLE tab ROW_FORMAT=DYNAMIC;
This workaround is a safe option, because the DYNAMIC row format may actually be able to store the data safely with this new table schema. See InnoDB DYNAMIC Row Format: Overflow Pages with the DYNAMIC Row Format for more information.
In MariaDB 10.2 and later, the DYNAMIC row format is the default row format. If your tables were originally created on one of these newer versions, then they may already be using this row format. In that case, you may need to use the next workaround.
Fitting More Columns on Overflow Pages
If the table is already using the DYNAMIC row format, then another safe option is to change the table schema, so that the row format can store more columns on overflow pages.
For VARCHAR columns, the DYNAMIC row format can only store these columns on overflow pages if the maximum length of the column is 256 bytes or longer. The original table schema is failing, because all of those small VARCHAR columns have to be stored on the row’s main data page. See InnoDB DYNAMIC Row Format: Overflow Pages with the DYNAMIC Row Format for more information.
Therefore, another safe workaround in a lot of cases is actually to increase the size of some variable-length columns, so that InnoDB’s row format can store them on overflow pages.
For example, when using InnoDB’s DYNAMIC row format and a default character set of latin1 (which requires up to 1 byte per character), the 256 byte limit means that a VARCHAR column will only be stored on overflow pages if it is at least as large as a varchar(256):
SET GLOBAL innodb_default_row_format='dynamic';
SET SESSION innodb_strict_mode=ON;
CREATE OR REPLACE TABLE tab (
col1 varchar(256) NOT NULL,
col2 varchar(256) NOT NULL,
col3 varchar(256) NOT NULL,
col4 varchar(256) NOT NULL,
col5 varchar(256) NOT NULL,
col6 varchar(256) NOT NULL,
col7 varchar(256) NOT NULL,
col8 varchar(256) NOT NULL,
col9 varchar(256) NOT NULL,
col10 varchar(256) NOT NULL,
col11 varchar(256) NOT NULL,
col12 varchar(256) NOT NULL,
col13 varchar(256) NOT NULL,
col14 varchar(256) NOT NULL,
col15 varchar(256) NOT NULL,
col16 varchar(256) NOT NULL,
col17 varchar(256) NOT NULL,
col18 varchar(256) NOT NULL,
col19 varchar(256) NOT NULL,
col20 varchar(256) NOT NULL,
col21 varchar(256) NOT NULL,
col22 varchar(256) NOT NULL,
col23 varchar(256) NOT NULL,
col24 varchar(256) NOT NULL,
col25 varchar(256) NOT NULL,
col26 varchar(256) NOT NULL,
col27 varchar(256) NOT NULL,
col28 varchar(256) NOT NULL,
col29 varchar(256) NOT NULL,
col30 varchar(256) NOT NULL,
col31 varchar(256) NOT NULL,
col32 varchar(256) NOT NULL,
col33 varchar(256) NOT NULL,
col34 varchar(256) NOT NULL,
col35 varchar(256) NOT NULL,
col36 varchar(256) NOT NULL,
col37 varchar(256) NOT NULL,
col38 varchar(256) NOT NULL,
col39 varchar(256) NOT NULL,
col40 varchar(256) NOT NULL,
col41 varchar(256) NOT NULL,
col42 varchar(256) NOT NULL,
col43 varchar(256) NOT NULL,
col44 varchar(256) NOT NULL,
col45 varchar(256) NOT NULL,
col46 varchar(256) NOT NULL,
col47 varchar(256) NOT NULL,
col48 varchar(256) NOT NULL,
col49 varchar(256) NOT NULL,
col50 varchar(256) NOT NULL,
col51 varchar(256) NOT NULL,
col52 varchar(256) NOT NULL,
col53 varchar(256) NOT NULL,
col54 varchar(256) NOT NULL,
col55 varchar(256) NOT NULL,
col56 varchar(256) NOT NULL,
col57 varchar(256) NOT NULL,
col58 varchar(256) NOT NULL,
col59 varchar(256) NOT NULL,
col60 varchar(256) NOT NULL,
col61 varchar(256) NOT NULL,
col62 varchar(256) NOT NULL,
col63 varchar(256) NOT NULL,
col64 varchar(256) NOT NULL,
col65 varchar(256) NOT NULL,
col66 varchar(256) NOT NULL,
col67 varchar(256) NOT NULL,
col68 varchar(256) NOT NULL,
col69 varchar(256) NOT NULL,
col70 varchar(256) NOT NULL,
col71 varchar(256) NOT NULL,
col72 varchar(256) NOT NULL,
col73 varchar(256) NOT NULL,
col74 varchar(256) NOT NULL,
col75 varchar(256) NOT NULL,
col76 varchar(256) NOT NULL,
col77 varchar(256) NOT NULL,
col78 varchar(256) NOT NULL,
col79 varchar(256) NOT NULL,
col80 varchar(256) NOT NULL,
col81 varchar(256) NOT NULL,
col82 varchar(256) NOT NULL,
col83 varchar(256) NOT NULL,
col84 varchar(256) NOT NULL,
col85 varchar(256) NOT NULL,
col86 varchar(256) NOT NULL,
col87 varchar(256) NOT NULL,
col88 varchar(256) NOT NULL,
col89 varchar(256) NOT NULL,
col90 varchar(256) NOT NULL,
col91 varchar(256) NOT NULL,
col92 varchar(256) NOT NULL,
col93 varchar(256) NOT NULL,
col94 varchar(256) NOT NULL,
col95 varchar(256) NOT NULL,
col96 varchar(256) NOT NULL,
col97 varchar(256) NOT NULL,
col98 varchar(256) NOT NULL,
col99 varchar(256) NOT NULL,
col100 varchar(256) NOT NULL,
col101 varchar(256) NOT NULL,
col102 varchar(256) NOT NULL,
col103 varchar(256) NOT NULL,
col104 varchar(256) NOT NULL,
col105 varchar(256) NOT NULL,
col106 varchar(256) NOT NULL,
col107 varchar(256) NOT NULL,
col108 varchar(256) NOT NULL,
col109 varchar(256) NOT NULL,
col110 varchar(256) NOT NULL,
col111 varchar(256) NOT NULL,
col112 varchar(256) NOT NULL,
col113 varchar(256) NOT NULL,
col114 varchar(256) NOT NULL,
col115 varchar(256) NOT NULL,
col116 varchar(256) NOT NULL,
col117 varchar(256) NOT NULL,
col118 varchar(256) NOT NULL,
col119 varchar(256) NOT NULL,
col120 varchar(256) NOT NULL,
col121 varchar(256) NOT NULL,
col122 varchar(256) NOT NULL,
col123 varchar(256) NOT NULL,
col124 varchar(256) NOT NULL,
col125 varchar(256) NOT NULL,
col126 varchar(256) NOT NULL,
col127 varchar(256) NOT NULL,
col128 varchar(256) NOT NULL,
col129 varchar(256) NOT NULL,
col130 varchar(256) NOT NULL,
col131 varchar(256) NOT NULL,
col132 varchar(256) NOT NULL,
col133 varchar(256) NOT NULL,
col134 varchar(256) NOT NULL,
col135 varchar(256) NOT NULL,
col136 varchar(256) NOT NULL,
col137 varchar(256) NOT NULL,
col138 varchar(256) NOT NULL,
col139 varchar(256) NOT NULL,
col140 varchar(256) NOT NULL,
col141 varchar(256) NOT NULL,
col142 varchar(256) NOT NULL,
col143 varchar(256) NOT NULL,
col144 varchar(256) NOT NULL,
col145 varchar(256) NOT NULL,
col146 varchar(256) NOT NULL,
col147 varchar(256) NOT NULL,
col148 varchar(256) NOT NULL,
col149 varchar(256) NOT NULL,
col150 varchar(256) NOT NULL,
col151 varchar(256) NOT NULL,
col152 varchar(256) NOT NULL,
col153 varchar(256) NOT NULL,
col154 varchar(256) NOT NULL,
col155 varchar(256) NOT NULL,
col156 varchar(256) NOT NULL,
col157 varchar(256) NOT NULL,
col158 varchar(256) NOT NULL,
col159 varchar(256) NOT NULL,
col160 varchar(256) NOT NULL,
col161 varchar(256) NOT NULL,
col162 varchar(256) NOT NULL,
col163 varchar(256) NOT NULL,
col164 varchar(256) NOT NULL,
col165 varchar(256) NOT NULL,
col166 varchar(256) NOT NULL,
col167 varchar(256) NOT NULL,
col168 varchar(256) NOT NULL,
col169 varchar(256) NOT NULL,
col170 varchar(256) NOT NULL,
col171 varchar(256) NOT NULL,
col172 varchar(256) NOT NULL,
col173 varchar(256) NOT NULL,
col174 varchar(256) NOT NULL,
col175 varchar(256) NOT NULL,
col176 varchar(256) NOT NULL,
col177 varchar(256) NOT NULL,
col178 varchar(256) NOT NULL,
col179 varchar(256) NOT NULL,
col180 varchar(256) NOT NULL,
col181 varchar(256) NOT NULL,
col182 varchar(256) NOT NULL,
col183 varchar(256) NOT NULL,
col184 varchar(256) NOT NULL,
col185 varchar(256) NOT NULL,
col186 varchar(256) NOT NULL,
col187 varchar(256) NOT NULL,
col188 varchar(256) NOT NULL,
col189 varchar(256) NOT NULL,
col190 varchar(256) NOT NULL,
col191 varchar(256) NOT NULL,
col192 varchar(256) NOT NULL,
col193 varchar(256) NOT NULL,
col194 varchar(256) NOT NULL,
col195 varchar(256) NOT NULL,
col196 varchar(256) NOT NULL,
col197 varchar(256) NOT NULL,
col198 varchar(256) NOT NULL,
PRIMARY KEY (col1)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
And when using InnoDB’s DYNAMIC row format and a default character set of utf8 (which requires up to 3 bytes per character), the 256 byte limit means that a VARCHAR column will only be stored on overflow pages if it is at least as large as a varchar(86):
SET GLOBAL innodb_default_row_format='dynamic';
SET SESSION innodb_strict_mode=ON;
CREATE OR REPLACE TABLE tab (
col1 varchar(86) NOT NULL,
col2 varchar(86) NOT NULL,
col3 varchar(86) NOT NULL,
col4 varchar(86) NOT NULL,
col5 varchar(86) NOT NULL,
col6 varchar(86) NOT NULL,
col7 varchar(86) NOT NULL,
col8 varchar(86) NOT NULL,
col9 varchar(86) NOT NULL,
col10 varchar(86) NOT NULL,
col11 varchar(86) NOT NULL,
col12 varchar(86) NOT NULL,
col13 varchar(86) NOT NULL,
col14 varchar(86) NOT NULL,
col15 varchar(86) NOT NULL,
col16 varchar(86) NOT NULL,
col17 varchar(86) NOT NULL,
col18 varchar(86) NOT NULL,
col19 varchar(86) NOT NULL,
col20 varchar(86) NOT NULL,
col21 varchar(86) NOT NULL,
col22 varchar(86) NOT NULL,
col23 varchar(86) NOT NULL,
col24 varchar(86) NOT NULL,
col25 varchar(86) NOT NULL,
col26 varchar(86) NOT NULL,
col27 varchar(86) NOT NULL,
col28 varchar(86) NOT NULL,
col29 varchar(86) NOT NULL,
col30 varchar(86) NOT NULL,
col31 varchar(86) NOT NULL,
col32 varchar(86) NOT NULL,
col33 varchar(86) NOT NULL,
col34 varchar(86) NOT NULL,
col35 varchar(86) NOT NULL,
col36 varchar(86) NOT NULL,
col37 varchar(86) NOT NULL,
col38 varchar(86) NOT NULL,
col39 varchar(86) NOT NULL,
col40 varchar(86) NOT NULL,
col41 varchar(86) NOT NULL,
col42 varchar(86) NOT NULL,
col43 varchar(86) NOT NULL,
col44 varchar(86) NOT NULL,
col45 varchar(86) NOT NULL,
col46 varchar(86) NOT NULL,
col47 varchar(86) NOT NULL,
col48 varchar(86) NOT NULL,
col49 varchar(86) NOT NULL,
col50 varchar(86) NOT NULL,
col51 varchar(86) NOT NULL,
col52 varchar(86) NOT NULL,
col53 varchar(86) NOT NULL,
col54 varchar(86) NOT NULL,
col55 varchar(86) NOT NULL,
col56 varchar(86) NOT NULL,
col57 varchar(86) NOT NULL,
col58 varchar(86) NOT NULL,
col59 varchar(86) NOT NULL,
col60 varchar(86) NOT NULL,
col61 varchar(86) NOT NULL,
col62 varchar(86) NOT NULL,
col63 varchar(86) NOT NULL,
col64 varchar(86) NOT NULL,
col65 varchar(86) NOT NULL,
col66 varchar(86) NOT NULL,
col67 varchar(86) NOT NULL,
col68 varchar(86) NOT NULL,
col69 varchar(86) NOT NULL,
col70 varchar(86) NOT NULL,
col71 varchar(86) NOT NULL,
col72 varchar(86) NOT NULL,
col73 varchar(86) NOT NULL,
col74 varchar(86) NOT NULL,
col75 varchar(86) NOT NULL,
col76 varchar(86) NOT NULL,
col77 varchar(86) NOT NULL,
col78 varchar(86) NOT NULL,
col79 varchar(86) NOT NULL,
col80 varchar(86) NOT NULL,
col81 varchar(86) NOT NULL,
col82 varchar(86) NOT NULL,
col83 varchar(86) NOT NULL,
col84 varchar(86) NOT NULL,
col85 varchar(86) NOT NULL,
col86 varchar(86) NOT NULL,
col87 varchar(86) NOT NULL,
col88 varchar(86) NOT NULL,
col89 varchar(86) NOT NULL,
col90 varchar(86) NOT NULL,
col91 varchar(86) NOT NULL,
col92 varchar(86) NOT NULL,
col93 varchar(86) NOT NULL,
col94 varchar(86) NOT NULL,
col95 varchar(86) NOT NULL,
col96 varchar(86) NOT NULL,
col97 varchar(86) NOT NULL,
col98 varchar(86) NOT NULL,
col99 varchar(86) NOT NULL,
col100 varchar(86) NOT NULL,
col101 varchar(86) NOT NULL,
col102 varchar(86) NOT NULL,
col103 varchar(86) NOT NULL,
col104 varchar(86) NOT NULL,
col105 varchar(86) NOT NULL,
col106 varchar(86) NOT NULL,
col107 varchar(86) NOT NULL,
col108 varchar(86) NOT NULL,
col109 varchar(86) NOT NULL,
col110 varchar(86) NOT NULL,
col111 varchar(86) NOT NULL,
col112 varchar(86) NOT NULL,
col113 varchar(86) NOT NULL,
col114 varchar(86) NOT NULL,
col115 varchar(86) NOT NULL,
col116 varchar(86) NOT NULL,
col117 varchar(86) NOT NULL,
col118 varchar(86) NOT NULL,
col119 varchar(86) NOT NULL,
col120 varchar(86) NOT NULL,
col121 varchar(86) NOT NULL,
col122 varchar(86) NOT NULL,
col123 varchar(86) NOT NULL,
col124 varchar(86) NOT NULL,
col125 varchar(86) NOT NULL,
col126 varchar(86) NOT NULL,
col127 varchar(86) NOT NULL,
col128 varchar(86) NOT NULL,
col129 varchar(86) NOT NULL,
col130 varchar(86) NOT NULL,
col131 varchar(86) NOT NULL,
col132 varchar(86) NOT NULL,
col133 varchar(86) NOT NULL,
col134 varchar(86) NOT NULL,
col135 varchar(86) NOT NULL,
col136 varchar(86) NOT NULL,
col137 varchar(86) NOT NULL,
col138 varchar(86) NOT NULL,
col139 varchar(86) NOT NULL,
col140 varchar(86) NOT NULL,
col141 varchar(86) NOT NULL,
col142 varchar(86) NOT NULL,
col143 varchar(86) NOT NULL,
col144 varchar(86) NOT NULL,
col145 varchar(86) NOT NULL,
col146 varchar(86) NOT NULL,
col147 varchar(86) NOT NULL,
col148 varchar(86) NOT NULL,
col149 varchar(86) NOT NULL,
col150 varchar(86) NOT NULL,
col151 varchar(86) NOT NULL,
col152 varchar(86) NOT NULL,
col153 varchar(86) NOT NULL,
col154 varchar(86) NOT NULL,
col155 varchar(86) NOT NULL,
col156 varchar(86) NOT NULL,
col157 varchar(86) NOT NULL,
col158 varchar(86) NOT NULL,
col159 varchar(86) NOT NULL,
col160 varchar(86) NOT NULL,
col161 varchar(86) NOT NULL,
col162 varchar(86) NOT NULL,
col163 varchar(86) NOT NULL,
col164 varchar(86) NOT NULL,
col165 varchar(86) NOT NULL,
col166 varchar(86) NOT NULL,
col167 varchar(86) NOT NULL,
col168 varchar(86) NOT NULL,
col169 varchar(86) NOT NULL,
col170 varchar(86) NOT NULL,
col171 varchar(86) NOT NULL,
col172 varchar(86) NOT NULL,
col173 varchar(86) NOT NULL,
col174 varchar(86) NOT NULL,
col175 varchar(86) NOT NULL,
col176 varchar(86) NOT NULL,
col177 varchar(86) NOT NULL,
col178 varchar(86) NOT NULL,
col179 varchar(86) NOT NULL,
col180 varchar(86) NOT NULL,
col181 varchar(86) NOT NULL,
col182 varchar(86) NOT NULL,
col183 varchar(86) NOT NULL,
col184 varchar(86) NOT NULL,
col185 varchar(86) NOT NULL,
col186 varchar(86) NOT NULL,
col187 varchar(86) NOT NULL,
col188 varchar(86) NOT NULL,
col189 varchar(86) NOT NULL,
col190 varchar(86) NOT NULL,
col191 varchar(86) NOT NULL,
col192 varchar(86) NOT NULL,
col193 varchar(86) NOT NULL,
col194 varchar(86) NOT NULL,
col195 varchar(86) NOT NULL,
col196 varchar(86) NOT NULL,
col197 varchar(86) NOT NULL,
col198 varchar(86) NOT NULL,
PRIMARY KEY (col1)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
And when using InnoDB’s DYNAMIC row format and a default character set of utf8mb4 (which requires up to 4 bytes per character), the 256 byte limit means that a VARCHAR column will only be stored on overflow pages if it is at least as large as a varchar(64):
SET GLOBAL innodb_default_row_format='dynamic';
SET SESSION innodb_strict_mode=ON;
CREATE OR REPLACE TABLE tab (
col1 varchar(64) NOT NULL,
col2 varchar(64) NOT NULL,
col3 varchar(64) NOT NULL,
col4 varchar(64) NOT NULL,
col5 varchar(64) NOT NULL,
col6 varchar(64) NOT NULL,
col7 varchar(64) NOT NULL,
col8 varchar(64) NOT NULL,
col9 varchar(64) NOT NULL,
col10 varchar(64) NOT NULL,
col11 varchar(64) NOT NULL,
col12 varchar(64) NOT NULL,
col13 varchar(64) NOT NULL,
col14 varchar(64) NOT NULL,
col15 varchar(64) NOT NULL,
col16 varchar(64) NOT NULL,
col17 varchar(64) NOT NULL,
col18 varchar(64) NOT NULL,
col19 varchar(64) NOT NULL,
col20 varchar(64) NOT NULL,
col21 varchar(64) NOT NULL,
col22 varchar(64) NOT NULL,
col23 varchar(64) NOT NULL,
col24 varchar(64) NOT NULL,
col25 varchar(64) NOT NULL,
col26 varchar(64) NOT NULL,
col27 varchar(64) NOT NULL,
col28 varchar(64) NOT NULL,
col29 varchar(64) NOT NULL,
col30 varchar(64) NOT NULL,
col31 varchar(64) NOT NULL,
col32 varchar(64) NOT NULL,
col33 varchar(64) NOT NULL,
col34 varchar(64) NOT NULL,
col35 varchar(64) NOT NULL,
col36 varchar(64) NOT NULL,
col37 varchar(64) NOT NULL,
col38 varchar(64) NOT NULL,
col39 varchar(64) NOT NULL,
col40 varchar(64) NOT NULL,
col41 varchar(64) NOT NULL,
col42 varchar(64) NOT NULL,
col43 varchar(64) NOT NULL,
col44 varchar(64) NOT NULL,
col45 varchar(64) NOT NULL,
col46 varchar(64) NOT NULL,
col47 varchar(64) NOT NULL,
col48 varchar(64) NOT NULL,
col49 varchar(64) NOT NULL,
col50 varchar(64) NOT NULL,
col51 varchar(64) NOT NULL,
col52 varchar(64) NOT NULL,
col53 varchar(64) NOT NULL,
col54 varchar(64) NOT NULL,
col55 varchar(64) NOT NULL,
col56 varchar(64) NOT NULL,
col57 varchar(64) NOT NULL,
col58 varchar(64) NOT NULL,
col59 varchar(64) NOT NULL,
col60 varchar(64) NOT NULL,
col61 varchar(64) NOT NULL,
col62 varchar(64) NOT NULL,
col63 varchar(64) NOT NULL,
col64 varchar(64) NOT NULL,
col65 varchar(64) NOT NULL,
col66 varchar(64) NOT NULL,
col67 varchar(64) NOT NULL,
col68 varchar(64) NOT NULL,
col69 varchar(64) NOT NULL,
col70 varchar(64) NOT NULL,
col71 varchar(64) NOT NULL,
col72 varchar(64) NOT NULL,
col73 varchar(64) NOT NULL,
col74 varchar(64) NOT NULL,
col75 varchar(64) NOT NULL,
col76 varchar(64) NOT NULL,
col77 varchar(64) NOT NULL,
col78 varchar(64) NOT NULL,
col79 varchar(64) NOT NULL,
col80 varchar(64) NOT NULL,
col81 varchar(64) NOT NULL,
col82 varchar(64) NOT NULL,
col83 varchar(64) NOT NULL,
col84 varchar(64) NOT NULL,
col85 varchar(64) NOT NULL,
col86 varchar(64) NOT NULL,
col87 varchar(64) NOT NULL,
col88 varchar(64) NOT NULL,
col89 varchar(64) NOT NULL,
col90 varchar(64) NOT NULL,
col91 varchar(64) NOT NULL,
col92 varchar(64) NOT NULL,
col93 varchar(64) NOT NULL,
col94 varchar(64) NOT NULL,
col95 varchar(64) NOT NULL,
col96 varchar(64) NOT NULL,
col97 varchar(64) NOT NULL,
col98 varchar(64) NOT NULL,
col99 varchar(64) NOT NULL,
col100 varchar(64) NOT NULL,
col101 varchar(64) NOT NULL,
col102 varchar(64) NOT NULL,
col103 varchar(64) NOT NULL,
col104 varchar(64) NOT NULL,
col105 varchar(64) NOT NULL,
col106 varchar(64) NOT NULL,
col107 varchar(64) NOT NULL,
col108 varchar(64) NOT NULL,
col109 varchar(64) NOT NULL,
col110 varchar(64) NOT NULL,
col111 varchar(64) NOT NULL,
col112 varchar(64) NOT NULL,
col113 varchar(64) NOT NULL,
col114 varchar(64) NOT NULL,
col115 varchar(64) NOT NULL,
col116 varchar(64) NOT NULL,
col117 varchar(64) NOT NULL,
col118 varchar(64) NOT NULL,
col119 varchar(64) NOT NULL,
col120 varchar(64) NOT NULL,
col121 varchar(64) NOT NULL,
col122 varchar(64) NOT NULL,
col123 varchar(64) NOT NULL,
col124 varchar(64) NOT NULL,
col125 varchar(64) NOT NULL,
col126 varchar(64) NOT NULL,
col127 varchar(64) NOT NULL,
col128 varchar(64) NOT NULL,
col129 varchar(64) NOT NULL,
col130 varchar(64) NOT NULL,
col131 varchar(64) NOT NULL,
col132 varchar(64) NOT NULL,
col133 varchar(64) NOT NULL,
col134 varchar(64) NOT NULL,
col135 varchar(64) NOT NULL,
col136 varchar(64) NOT NULL,
col137 varchar(64) NOT NULL,
col138 varchar(64) NOT NULL,
col139 varchar(64) NOT NULL,
col140 varchar(64) NOT NULL,
col141 varchar(64) NOT NULL,
col142 varchar(64) NOT NULL,
col143 varchar(64) NOT NULL,
col144 varchar(64) NOT NULL,
col145 varchar(64) NOT NULL,
col146 varchar(64) NOT NULL,
col147 varchar(64) NOT NULL,
col148 varchar(64) NOT NULL,
col149 varchar(64) NOT NULL,
col150 varchar(64) NOT NULL,
col151 varchar(64) NOT NULL,
col152 varchar(64) NOT NULL,
col153 varchar(64) NOT NULL,
col154 varchar(64) NOT NULL,
col155 varchar(64) NOT NULL,
col156 varchar(64) NOT NULL,
col157 varchar(64) NOT NULL,
col158 varchar(64) NOT NULL,
col159 varchar(64) NOT NULL,
col160 varchar(64) NOT NULL,
col161 varchar(64) NOT NULL,
col162 varchar(64) NOT NULL,
col163 varchar(64) NOT NULL,
col164 varchar(64) NOT NULL,
col165 varchar(64) NOT NULL,
col166 varchar(64) NOT NULL,
col167 varchar(64) NOT NULL,
col168 varchar(64) NOT NULL,
col169 varchar(64) NOT NULL,
col170 varchar(64) NOT NULL,
col171 varchar(64) NOT NULL,
col172 varchar(64) NOT NULL,
col173 varchar(64) NOT NULL,
col174 varchar(64) NOT NULL,
col175 varchar(64) NOT NULL,
col176 varchar(64) NOT NULL,
col177 varchar(64) NOT NULL,
col178 varchar(64) NOT NULL,
col179 varchar(64) NOT NULL,
col180 varchar(64) NOT NULL,
col181 varchar(64) NOT NULL,
col182 varchar(64) NOT NULL,
col183 varchar(64) NOT NULL,
col184 varchar(64) NOT NULL,
col185 varchar(64) NOT NULL,
col186 varchar(64) NOT NULL,
col187 varchar(64) NOT NULL,
col188 varchar(64) NOT NULL,
col189 varchar(64) NOT NULL,
col190 varchar(64) NOT NULL,
col191 varchar(64) NOT NULL,
col192 varchar(64) NOT NULL,
col193 varchar(64) NOT NULL,
col194 varchar(64) NOT NULL,
col195 varchar(64) NOT NULL,
col196 varchar(64) NOT NULL,
col197 varchar(64) NOT NULL,
col198 varchar(64) NOT NULL,
PRIMARY KEY (col1)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;







 Roy Hasson is a Global Business Development Manager for AWS Analytics. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family.
Roy Hasson is a Global Business Development Manager for AWS Analytics. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family.
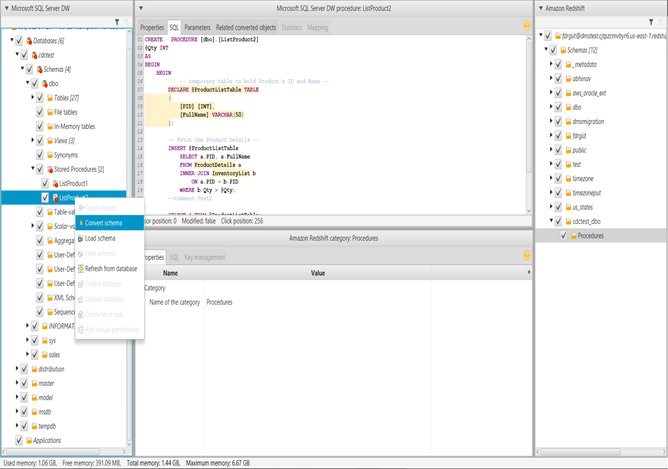
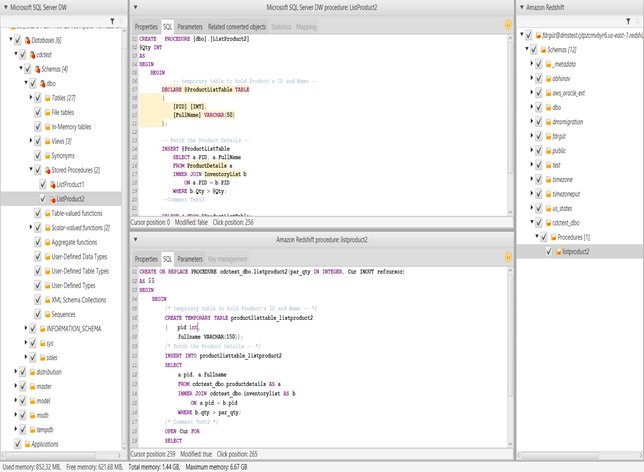
 Joe Harris is a senior Redshift database engineer at AWS, focusing on Redshift performance. He has been analyzing data and building data warehouses on a wide variety of platforms for two decades. Before joining AWS he was a Redshift customer from launch day in 2013 and was the top contributor to the Redshift forum.
Joe Harris is a senior Redshift database engineer at AWS, focusing on Redshift performance. He has been analyzing data and building data warehouses on a wide variety of platforms for two decades. Before joining AWS he was a Redshift customer from launch day in 2013 and was the top contributor to the Redshift forum.  Abhinav Singh is a database engineer at AWS. He works on design and development of database migration projects as well as customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
Abhinav Singh is a database engineer at AWS. He works on design and development of database migration projects as well as customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS. Entong Shen is a senior software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 7 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Entong Shen is a senior software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 7 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden. Vinay is a principal product manager at Amazon Web Services for Amazon Redshift. Previously, he was a senior director of product at Teradata and a director of product at Hortonworks. At Hortonworks, he launched products in Data Science, Spark, Zeppelin, and Security. Outside of work, Vinay loves to be on a yoga mat or on a hiking trail.
Vinay is a principal product manager at Amazon Web Services for Amazon Redshift. Previously, he was a senior director of product at Teradata and a director of product at Hortonworks. At Hortonworks, he launched products in Data Science, Spark, Zeppelin, and Security. Outside of work, Vinay loves to be on a yoga mat or on a hiking trail. In this blog post, we will discuss a new feature – the MySQL 8.0.17
In this blog post, we will discuss a new feature – the MySQL 8.0.17 














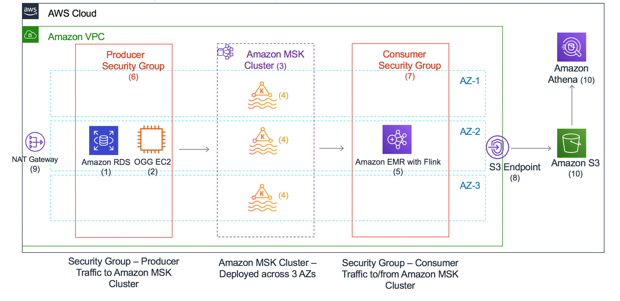

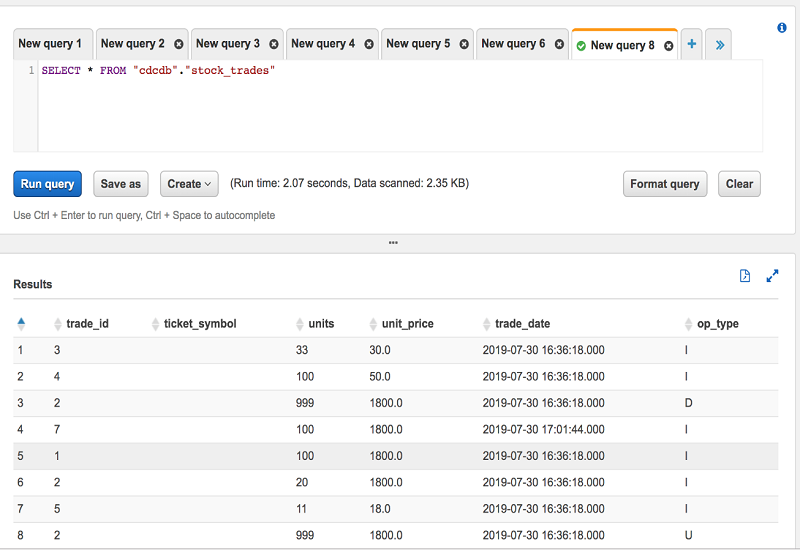
 Sreekanth Krishnavajjala is a solutions architect at Amazon Web Services.
Sreekanth Krishnavajjala is a solutions architect at Amazon Web Services. Vinod Kataria is a senior partner solutions architect at Amazon Web Services.
Vinod Kataria is a senior partner solutions architect at Amazon Web Services.