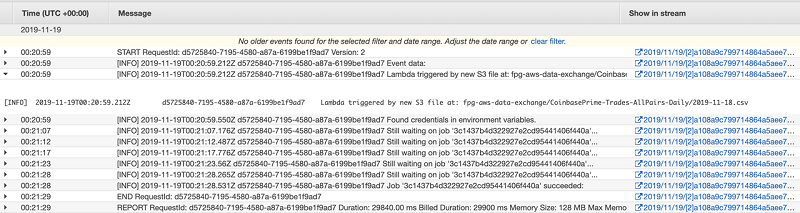
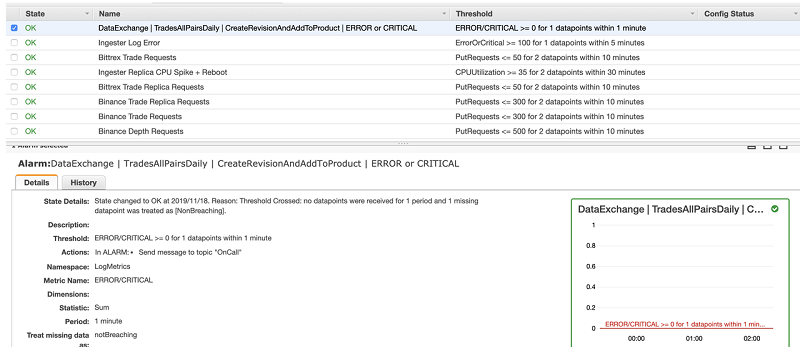
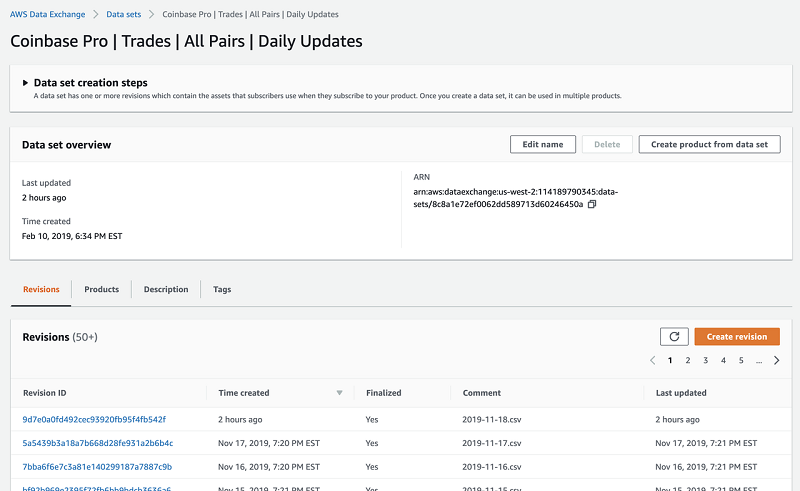
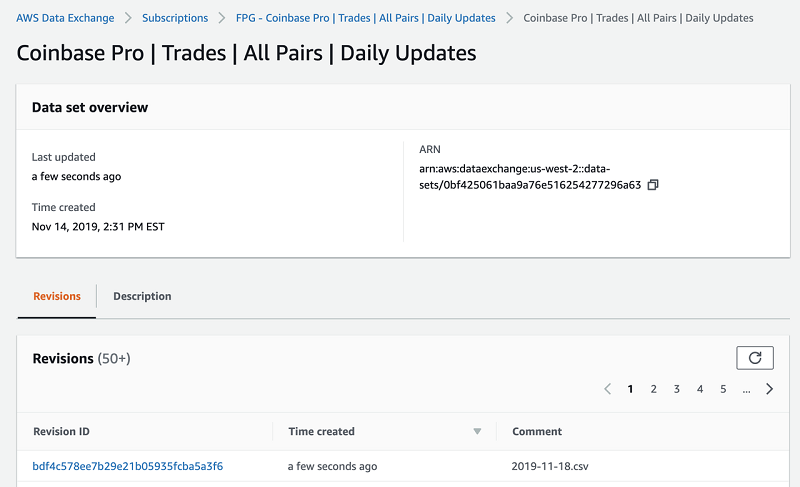
Feed: MemSQL Blog.
Author: Floyd Smith.
With the MemSQL 7. 0 release, MemSQL has added more special-purpose features, making it even easier to manage time series data within our best-of-breed operational database. These new features allow you to structure queries on time series data with far fewer lines of code and with less complexity. With time series features in MemSQL, we make it easier for any SQL user, or any tool that uses SQL, to work with time series data, while making expert users even more productive. In a recent webinar (view the recording here), Eric Hanson described the new features and how to use them.
The webinar begins with an overview of MemSQL, then describes how customers have been using MemSQL for time series data for years, prior to the MemSQL 7.0 release. Then there’s a description of the time series features that MemSQL has added, making it easier to query and manage time series data, and a Q&A section at the end.
Introducing MemSQL
MemSQL is a very high-performance scalable SQL relational database system. It’s really good for scalable operations, both for transaction processing and analytics on tabular data. Typically, it can be as much as 10 times faster, and three times more cost-effective, than legacy database providers for large volumes under high concurrency.
We like to call MemSQL the No-Limits Database because of its amazing scalability. It’s the cloud-native operational database that’s built for speed and scale. We have capabilities to support operational analytics. So, operational analytics is when you have to deliver very high analytical performance in an operational database environment where you may have concurrent updates and queries running at an intensive, demanding level. Some people like to say that it’s when you need “Analytics with an SLA.”
Now, I know that everybody thinks they have an SLA when they have an analytical database, but when you have a really demanding SLA like requiring interactive, very consistent response time in an analytical database environment, under fast ingest, and with high concurrency, that’s when MemSQL really shines.
We also support predictive ML and AI capabilities. For example, we’ve got some built-in functions for vector similarity matching. Some of our customers were using MemSQL in a deep learning environment to do things like face and image matching and customers are prototyping applications based on deep learning like fuzzy text matching. The built-in dot product and Euclidean distance functions we have can help you make those applications run with very high performance. (Nonprofit Thorn is one organization that uses these ML and AI-related capabilities at the core of their app, Spotlight, which helps law enforcement identify trafficked children. – Ed.)
Also, people are using MemSQL when they need to move to cloud or replace legacy relational database systems. When they reach some sort of inflection point, like they know they need to move to cloud, they want to take advantage of the scalability of the cloud, they want to consider a truly scalable product, and so they’ll look at MemSQL. Also, when it comes time to re-architect the legacy application – if, say, the scale of data has grown tremendously, or is expected to change in the near future, people really may decide they need to find a more scalable and economical platform for their relational data, and that may prompt them to move to MemSQL.
Here are examples of the kinds of workloads and customers we support: Half of the top 10 banks banks in North America, two of the top three telecommunications companies in North America, over 160 million streaming media users, 12 of the Fortune 50 largest companies in the United States, and technology leaders from Akamai to Uber.
If you want to think about MemSQL and how it’s different from other database products, you can think of it as a very modern, high-performance, scalable SQL relational database. We have all three: speed, scale, and SQL. We get our speed because we compile queries to machine code. We also have in-memory data structures for operational applications, an in-memory rowstore structure, and a disk-based columnstore structure.
![MemSQL is the No-Limits Database]()
We compile queries to machine code and we use vectorized query execution on our columnar data structure. That gives us tremendous speed on a per-core basis. We’re also extremely scalable. We’re built for the cloud. MemSQL is a cloud-native platform that can gang together multiple computers to handle the work for a single database, in a very elegant and high-performance fashion. There’s no real practical limit to scale when using MemSQL.
Finally, we support SQL. There are some very scalable database products out there in the NoSQL world that are fast for certain operations, like put and get-type operations that can scale. But if you try to use these for sophisticated query processing, you end up having to host a lot of the query processing logic in the application, even to do simple things like joins. It can make your application large and complex and brittle – hard to evolve.
So SQL, the relational data model, was invented by EF Codd (PDF) – back around 1970 – for a reason. To separate your query logic from the physical data structures in your database, and to provide a non-procedural query language that makes it easier to find the data that you want from your data set. The benefits that were put forth when the relational model was invented are still true today.
We’re firmly committed to relational database processing and non-procedural query languages with SQL. There’s tremendous benefits to that, and you can have the best of both. You can have speed, and you can have scale, along with SQL. That’s what we provide.
How does MemSQL fit into the rest of your data management environment? MemSQL provides tremendous support for analytics, application systems like dashboards, ad-hoc queries, and machine learning. Also other types of applications like real-time decision-making apps, Internet of Things apps, dynamic user experiences. The kind of database technology that was available before couldn’t provide the real-time analytics that are necessary to give the truly dynamic user experience people are looking for today; we can provide that.
![MemSQL architectural chart CDC and data types]()
We also provide tremendous capabilities for fast ingest and change data capture (CDC). We have the ability to stream data into MemSQL from multiple sources like file systems and Kafka. We have a feature called Pipelines, which is very popular, to automatically load data from file folders, AWS S3, Kafka. You can transform data as it’s flowing into MemSQL, with very little coding. We support a very high performance and scalable bulk load system.
We have support for a large variety of data types including relational data, standard structured data types, key-value, JSON, geospatial, time-oriented data, and more. We run everywhere. You can run MemSQL on-premises, you can run it in the cloud as a managed database platform, or as a service in our new Helios system, which just was delivered in September.
We also allow people to self-host in the cloud. If they want full control over how their system is managed, they can self-host on all the major cloud providers and also run in containers; so, wherever you need to run, we are available.
I mentioned scalability earlier and I wanted to drill into that a little bit to illustrate the, how our platform is organized. MemSQL provides an image to the database client application as just, it’s just a database. You have a connection string, you connect, you set your connection to use us as a database, and you can start submitting SQL statements. It’s a single system image. The application doesn’t really know that MemSQL is distributed – but, underneath the sheets, it’s organized as you see in this diagram.
![MemSQL node and leaf architecture]()
There are one or more aggregator nodes, which are front-end nodes that the client application connects to. Then, there can be multiple back-end nodes. We call them leaf nodes. The data is horizontally partitioned across the leaf nodes – some people call this sharding. Each leaf node has one or more partitions of data. Those partitions are defined based on some data definition language (DDL); when you create your table, you define how to shard the data across nodes.
MemSQL’s query processor knows how to take a SQL statement and divide it up into smaller units of work across the leaf nodes, and final assembly results is done by the aggregator node. Then, the results are sent back for the client. As you need to scale, you can add additional leaf nodes and rebalance your data, so that it’s easy to scale the system up and down as needed.
How Customers Have Used MemSQL for Time Series Data
So with that background on MemSQL, let’s talk about using MemSQL for time series data. First of all, for those of you who are not really familiar with time series, a time series is simply a time-ordered sequence of events of some kind. Typically, each time series entry has, at least, a time value and some sort of data value that’s taken at that time. Here’s an example time series of pricing of a stock over time, over like an hour and a half or so period.
![MemSQL time series stock prices]()
You can see that the data moves up and down as you advance in time. Typically, data at any point in time is closely correlated to the immediately previous point in time. Here’s another example, of flow rate. People are using MemSQL for energy production, for example, in utilities. They may be storing and managing data representing flow rates. Here’s another example, a long-term time series of some health-oriented data from the US government, from the Centers for Disease Control, about chronic kidney disease over time.
These are just three examples of time series data. Virtually every application that’s collecting business events of any kind has a time element to it. In some sense, almost all applications have a time series aspect to them.
Let’s talk about time series database use cases. It’s necessary, when you’re managing time-oriented data, to store new time series events or entries, to retrieve the data, to modify time series data – to delete or append or truncate the data, or in some cases, you may even update the data to correct an error. Or you may be doing some sort of updating operation where you are, say, accumulating data for a minute or so. Then, once the data has sort of solidified or been finalized, you will no longer update it. There are many different modification scenarios for time series data.
Another common operation on time series data is to do things like convert an irregular time series to a regular time series. For example, data may arrive with a random sort of arrival process, and the spacing between events may not be equal, but you may want to convert that to a regular time series. Like maybe data arrives every 1 to 10 seconds, kind of at random. You may want to create a time series which has exactly 1 data point every 15 seconds. That’s an example of converting from an irregular to a regular time series.
![MemSQL time series use cases]()
Another kind of operation on time series is to downsample. That means you may have a time series with one tick every second, maybe you want to have one tick every one minute. That’s downsampling. Another common operation is smoothing. So you may have some simple smoothing capability, like a five-second moving average of a time series, where you average together like the previous five seconds worth of data from the series, or a more complex kind of smoothing – say, where you fit a curve through the data to smooth it , such as a spline curve. There are many, many more kind of time series use cases.
A little history about how MemSQL has been used for time series is important to give, for context. Customers already use MemSQL for time series event data extensively, using our previously shipped releases, before the recent shipment of MemSQL 7.0 and its time series-specific features. Lots of our customers store business events with some sort of time element. We have quite a few customers in the financial sector that are storing financial transactions in MemSQL. Of course, each of these has a time element to it, recording when the transaction occurred.
![MemSQL Time series plusses]()
Also, lots of our customers have been using us for Internet of Things (IoT) events. For example, in utilities, in energy production, media and communications, and web and application development. For example, advertising applications. As I mentioned before, MemSQL is really tremendous for fast and easy streaming. With our pipelines capability, it’s fast and easy to use load data, and just very high-performance insert data manipulation language (DML). You can do millions of inserts per second on a MemSQL cluster.
We have a columnstore storage mechanism which has tremendous compression – typically, in the range of 5x to 10x, compared to raw data. It’s easy to store a very large volume of historical data in a columnstore table in MemSQL. Because of the capabilities that MemSQL provides for high scalability, high-performance SQL, fast, and easy ingest, and high compression with columnar data storage. All those things have made MemSQL really attractive destination for people that are managing time series data.
New Time Series Features in MemSQL 7.0
(For more on what’s in MemSQL 7.0, see our release blog post, our deep dive into resiliency features, and our deep dive into MemSQL SingleStore. We also have a blog post on our time series features. – Ed.)
Close to half of our customers are using time series in some form, or they look at the data they have as time series. What we wanted to do for the 7.0 release was to make time series querying easier. We looked at some of our customers’ applications, and some internal applications we had built on MemSQL for historical monitoring. We saw that, while the query language is very powerful and capable, it looked like some of the queries could be made much easier.
![MemSQL easy time series queries]()
We wanted to provide a very brief syntax to let people write common types of queries – to do things like downsampling, or converting irregular time series to regular time series. You want to make that really easy. We wanted to let the more typical developers do things they couldn’t do before with SQL because it was just too hard. Let experts do more, and do it faster ,so they could spend more time on other parts of their application rather than writing tricky queries to extract information from time series.
So that said, we were not trying to be the ultimate time series specialty package. For example, if you need curve fitting, or very complex kinds of smoothing ,or you need to add together two different time series, for example. We’re not really trying to enable those use cases to be as easy and fast as they can be. We’re looking at sort of a conventional ability to manage large volumes of time series data, ingest the time series fast, and be able to do typical and common query use cases through SQL easily. That’s what we want to provide. If you need some of these specialty capabilities, you probably want to consider a more specialized time series product like KBB+ or something similar to that.
Throughout the rest of the talk, I’m going to be referring a few times to an example based on candlestick charts. A candlestick chart is a typical kind of chart used in the financial sector to show high, low, open, and close data for a security, during some period of time – like an entire trading day, or by minute, or by hour, et cetera.
![MemSQL time series candlestick chart]()
This graphic shows a candlestick chart with high, low, open, close graphic so that the little lines at the top and bottom show the high and low respectively. Then, the box shows the open and close. Just to start off with, I wanted to show a query using MemSQL 6.8 to calculate information that is required to render a candlestick chart like you see here.
![MemSQL time series old and new code]()
On the left side, this is a query that works in MemSQL 6.8 and earlier to produce a candlestick chart from a simple series of financial trade or transaction events. On the right-hand side, that’s how you write the exact same query in MemSQL 7.0. Wow. Look at that. It’s about one third as many characters as you see on the left, and also it’s much less complex.
On the left, you see you’ve got a common table expression with a nested select statement that’s using window functions, sort of a relatively complex window function, and several aggregate functions. It’s using rank, and then using a trick to pick out the top-ranked value at the bottom. Anyway, that’s a challenging query to write. That’s an expert-level query, and even experts struggle a little bit with that. You might have to refer back to the documentation.
I’ll go over this again in a little more detail, but just please remember this picture. Look how easy it is to manage time series data to produce a simple candlestick chart on the right compared to what was required previously. How did we enable this? We provide some new time series functions and capabilities in MemSQL 7.0 that allowed us to write that query more easily.
![New MemSQL time series functions]()
We provide three new built-in functions: FIRST(), LAST(), and TIME_BUCKET(). FIRST() and LAST() are aggregate functions that provide the first or last value in a time window or group, based on some time period that defines an ordering. I’ll say more about those in a few minutes. TIME_BUCKET() is a function that maps a timestamp to a one-minute or five-minute or one-hour window, or one-day window, et cetera. It allows you to do it in a very easy way with a very brief syntax, that’s fairly easy to learn and remember.
Finally, we’ve added a new designation called the SERIES TIMESTAMP column designation, which allows you to mark one of your columns as the time column for your time series. That allows some shorthand notations that I’ll talk about more.
![Time series timestamp example]()
Here’s a very simple example table that holds time series data for financial transactions. We’ve got a ts column, that’s a datetime 6 marked as the series timestamp. The data type is datetime 6, which is, it’s standard datetime with six places to the right of the decimal point. It’s accurate down to the microsecond. Symbol is like a stock symbol, a character string up to five characters. Price is a decimal, with up to 18 digits in 4 places to the right of the decimal point. So very simple time series table for financial information.
Some examples that are going to follow, I’m going to use this simple data set. Now, we’ve got two stocks, made-up stocks, ABC and XYZ that have some data that’s arrived in a single day, February 18th of next year, in a period of a few minutes. We’ll use that data and some examples set in the future.
Let’s look in more detail at the old way of querying time series data with MemSQL using window functions. I want to, for each symbol, for each hour, produce high, low, open, and close. This uses a window function that partitions by a time bucket. The symbol and time bucket ordered by timestamp, and the rows are between unbounded preceding and unbounded following. “Unbounded” means that any aggregates we calculate over this window will be over the entire window.
![Old code for time series with SQL]()
Then, we compute the rank, which is the serial number based on the sort order like 1, 2, 3, 4, 5. One is first, two is second, so forth. Then, the minimum and maximum over the window, and first value and last value over the window. First value and last value are the very original value and the very final value in the window, based on the sort order of the window. Then, you see that from Unix time, Unix timestamp, ts divided by 60 times 60, times 60 times 60.
This is a trick that people who manage time series data with SQL have learned. Basically, you can multiply, you can divide a timestamp by a window, and then multiply by the window again, and that will chunk up a fine-grain timestamp into a coarser grain that is bound at a window boundary. In this case, it’s 60 times 60. Then, finally, the select block at the end, you’ve got, you’re selecting the time series, the timestamp from above the symbol, min price, max price, first, last, but above that produced an entry for every single point in the series, so we really only want one. We pick out the top-ranked one.
Anyway, this is tricky. I mean, this is the kind of thing that will take an expert user from several minutes, to many minutes, to write, and with references back to the documentation. Can we do better than this? How can we do better? We introduced first and last as regular aggregate functions, in order to enable this kind of use case, with less code. We’ve got a very basic example. Now, select first, price, ts from tick, but the second argument to the first aggregate is a timestamp, but it’s optional.
If it’s not present, then we infer that you meant to use the series timestamp column of the table that you’re querying. The top one is the full notation, but in the bottom query, you say select first price, last price from tick. That first price and last price from tick implicitly use the series timestamp column ts as the time argument, the second argument to those aggregate functions. It just makes the query easier to write. You don’t have to remember to explicitly put in the series time value in the right place when you use those functions.
Next, we have a new function for time bucketing. You don’t have to write that tricky divide, and then that multiply kind of expression that I showed you before. Much, much easier to use, more intuitive. Time bucket takes a bucket width, and that’s a character string like 5m, for five minutes, 1h for one hour, and so forth. Then, two optional arguments – the time and the origin.
![New code with MemSQL Time Series functions]()
The time is optional just like before. If you don’t use it, if you don’t specify it, then we implicitly add the series timestamp column from the table or table, from the table that you’re querying. Then, origin allows you to provide an offset. For example, if you want to do time bucketing but start at 8:000 AM every day, you want a bucket by day but start your day at 8AM instead of midnight, then you can put in an origin argument.
Again, this is far easier than the tricky math expression that we used for that candlestick query before. Here’s some example of uses of origin with an 8AM origin. For example, we’ve got this table T with that, and ts is the series timestamp ,and v is a value that’s a double-precision float. You see the query there in the middle: select time bucket 1d ts, and then you pick a date near the timestamps that you’re working with, and provide… That’s your origin. It’s an 8AM origin.
Then, some of these. You can see down below that the days, the day bucket boundaries are starting at 8AM. Normally, you’re not going to need to use an origin, but if you do have that need to have an offset you can do that. Again, let’s look at the new way of answering, providing the candlestick chart query. This uses, we say select time bucket 1h, which is a one hour bucket. Then, the symbol, the minimum price, the maximum price, the first price, and the last price.
Notice that in first and last and time bucket, we don’t even have to refer to the timestamp column in the original data set, because it’s implicit. Some of you may have worked with specialty products for managing web events like Splunk or Azure Kusto, and so this concept of using a time bucket function or a bucket function with an easy notation like this, you may be familiar with that from those kind of systems.
One of the reason people like those products so much for the use cases that they’re designed for is that it’s really easy to query the data. The queries are very brief. We try to bring that brevity for time series data to SQL with this new capability, with the series timestamp that’s an implicit argument to these functions. Then, just group by 2, 1, which is the time bucket and the symbol and order by 2, 1. So, very simple query expression.
Just to recap, MemSQL for several years has been great for time series ingest and storage. People loved it for that. We have very fast ingest, powerful SQL capability, with time-oriented functions as part of our window function capability. High-performance query processing based on compilation to machine code and vectorization, as well as scalability through scale-out and also the ability to support high concurrency, where you’ve got lots of writers and readers concurrently working on the same data set. And not to mention, we provide transactions, support, easy manageability, and we’re built for the cloud.
Now, given all the capabilities we already had, we’re making it even easier to query time series data with this new brief syntax, these new functions, first, last, and time bucket in the series timestamp concept, that allows you to write queries very briefly, without having to reference, repeatedly and redundantly, to the time column in your table.
![Time series functions recap]()
This lets non-expert users do more than they could before, things they just weren’t capable of before with time series data, and it makes experts users more productive. I’d like to invite you to try MemSQL for free today, or contact Sales. Try it for free by using our free version, or go on Helios and do an eight-hour free trial. Either way, you can try MemSQL for no charge. Thank you.
Q&A: MemSQL and Time Series
Q. What’s the best way to age out old data from a table storing time series data?
A. The life cycle management of time series data is really important in any kind of time series application. One of the things you need to do is eliminate or purge old data. It’s really pretty easy to do that in MemSQL. All you have to do is run a delete statement periodically to delete the old data. Some other database products have time-oriented partitioning capabilities, and their delete is really slow, so they require you to, for instance, swap out an old partition once a month or so to purge old data from a large table. In MemSQL, you don’t really need to do that, because our delete is really, really fast. We can just run a delete statement to delete data prior to a certain time, whenever you need to remove old data.
Q. Can you have more than one time series column in a table?
A. You can only designate one column in a table as the series timestamp. However, you can have multiple time columns in a table and if you want to use different columns, you can use those columns explicitly with our new built-in time functions – FIRST(), LAST(), and TIME_BUCKET().There’s an optional time argument, so if you want to have like a secondary time on a table that’s not your primary series time stamp, but you want to use it for some of those functions, you can do it. You just have to name the time column explicitly in the FIRST(), LAST(), and TIME_BUCKET() functions.
Q. Does it support multi-tenancy?
A. Does it support multi-tenancy? Sure. MemSQL supports any number of concurrent users, up a very high number of concurrent queries. You can have multiple databases on a single cluster, and each application can have its own database if you want to, to have multi-tenant applications running on the same cluster.
Q. Does MemSQL keep a local copy of the data ingested or does it only keep references? If MemSQL keeps a local copy, how is it kept in sync with external sources?
A. MemSQL is a database system. You create tables, you insert data in the tables, you query data in the tables, you can update the data, delete it. So when you add a record to MemSQL it, that record, a copy of the information and that record, the record itself is kept in MemSQL. It doesn’t store data by reference, it stores copies of the data. If you want to keep it in sync with external sources, you need to, as the external values change, you’ll need to update the record that represents that information in MemSQL.
Q. How can you compute a moving average on a time series in MemSQL?
A. Sure. You can compute a moving average; it depends on how you want to do it. If you just want to average the data in each time bucket, you can just use average to do that. If you want to do a moving average, you can use window functions for that, and you can do an average over a window as it moves. You can average over a window from three preceding rows, to the current row, to average the last four values.
Q. Did you mention anything about Python interoperability? In any event, what Python interface capabilities do you offer?
A. We do have Python interoperability – in that, you can let client applications that connect to MemSQL and insert data, query data, and so forth in just about any popular query language. We support connectivity to applications through drivers that are MySQL wire protocol-compatible. Essentially, any application software that can connect to the MySQL database and insert data, update data, and so forth, can also connect to MemSQL.
We have drivers for Python that allow you to write a Python application and connect it to MemSQL. In addition, in our Pipeline capability, we support what are called transforms. Those are programs or scripts that can be applied to transform batches of information that are flowing into MemSQL through the Pipeline. You can write transforms in Python as well.
Q. Do I need to add indexes to be able to run fast select queries on time series data, with aggregations?
A. So, depending on the nature of the queries and how much data you have, how much hardware you have, you may or may not need to use indexes to make certain queries run fast. I mean, it really depends on your data and your queries. If you have very large data sets and high-selectivity queries and a lot of concurrency, you’re probably going to want to use indexes. We support indexes on our rowstore table type, both ordered indexes and hash indexes.
Then, our columnstore table type, we have a sort key, a primary sort key, which is like an index in some ways, as well as support for secondary hash indexes. However, the ability to share your data across multiple nodes in a large cluster and use columnstore, data storage structures that with very fast vectorized query execution makes it possible to run queries with response times of a fraction of a second, on very large data sets, without an index.
That can make it easier as an application developer, you can let the power of your computing cluster and database software just make it easier for you and not have to be so clever about defining your indexes. Again, it really depends on the application.
Q. Can you please also talk about encryption and data access roles, management for MemSQL?
A. With respect to encryption, for those customers that want to encrypt their data at rest, we recommend that they use Linux file system capabilities or cloud storage platform capabilities to do that, to encrypt the data through the storage layer underneath the database system.
Then, with respect to access control, MemSQL has a comprehensive set of data access capabilities. You can grant permission to access tables and views to different users or groups. We support single sign-on through a number of different mechanisms. We have a pretty comprehensive set of access control policies. We also support row-level security.
Q. What of row locking will I struggle kind with by using many transactions, selects, updates, deletes at once?
MemSQL has multi-version concurrency control, so readers don’t block writers and vice versa. Write-Write conflicts usually happen at row-level lock granularity.
Q. How expensive is it to reindex a table?
A. CREATE INDEX is typically fast. I have not heard customers have problems with it.
Q. Your reply on moving averages seem to pertain to simple moving averages, but how would you do exponential moving averages or weighted moving averages where a windows function may not be appropriate?
A. For that you’d have to do it in the client application or in a stored procedure. Or consider using a different time series tool.
Q. Are there any utilities available for time series data migration to / from an existing datastores like Informix,
A. For straight relational table migration, yes. But you’d have to probably do some custom work to move data from a time series DataBlade in Informix to regular tables in MemSQL.
Q. Does series timestamp accept integer data type or it has to be datetime data type?
A. The data type must be time or datetime or timestamp. Timestamp is not recommended because it has implied update behavior.
Q. Any plans to support additional aggregate functions with the time series functions? (e.g. we would have liked to get percentiles like first/last without the use of CTEs)
A. Percentile_cont and percentile_disc work in MemSQL 7.0 as regular aggs. If you want other aggs, let us know.
Q. Where can I find more info on AI (ML & DL) in MemSQL?
A. See the documentation for dot_product and euclidean_distance functions. And see webinar recordings about this from the past. And see blog: https://www.memsql.com/blog/memsql-data-backbone-machine-learning-and-ai/
Q. Can time series data be associated with asset context and queried in asset context. (Like a tank, with temperature, pressure, etc., within the asset context of the tank name.)
A. A time series record can have one timestamp and multiple fields. So I think you could use regular string table fields for context and numeric fields for metrics to plot and aggregate.
Q. Guessing the standard role based security model exists to restrict access to time series data.
A. Yes.
(End of Q&A)
We invite you to learn more about MemSQL at https://www.memsql.com, or give us a try for free at https://www.memsql.com/free.